In the first and second part of this series I described how to set up the hardware to read data from the OBD port using a Raspberry Pi and then upload it to the cloud. You should read the first part and second part of this series before you read this article.
Having done all the work to capture and transport all the data to the cloud, let us figure out what can be done on the cloud to introduce Machine Learning. To understand the concepts given in this article you will need to be familiar with Javascript and Python. Also, I am using MongoDB as my database - so you will need to know the basics of a document-oriented database to follow the example code here. MongoDB is not only my storage engine here, but also my compute engine. By that, I mean that I am using the database's scripting language (Javascript) to pre-process data that will ultimately be used for machine learning. The Javascript code given herein executes (in a distributed manner) inside the MongoDB database. (Some people get confused when they see Javascript, assuming that it requires a server like NodeJS to run - not here.)
Introduction to the Solution
To set the introduction, I will describe the following three tasks in this article:

- Read the raw records and augment it with additional derived information to generate some extra features used for machine learning that is not directly sent by the Raspberry Pi. Derivatives based on time interval between readings can be used to derive instanteous velocity, angular velocity and incline. These are inserted into the derived records when we save it to another MongoDB collection (also known as 'table' in relational database parlance) to be used later for generating the feature sets. I will be calling this collection 'mldataset' in my database.
- Read the 'mldataset' and extract features from the records. The feature set is saved into another collection called 'vehicle_signature_records'. This is an involved process since there are so many fields found in the raw records. In my case, the feature sets are basically three statistical averages (minimum, average and maximum) of all values aggregated over a 15 second period. The other research papers on this subject take the same approach, but the time interval over which the aggregates are taken vary based on the frequency of the readings. The recommended frequency is 5 Hz i.e. 1 record-set per 0.2 second. But as I mentioned in article 2 of this series, we are unable to read data that fast on a serial connection over ELM 327. The maximum speed that I have been able to observe (mostly in modern cars) is 1 record-set in 0.7 seconds. Thus a 15 second aggregation makes more sense in our scenario. Due to this, the accuracy of the prediction may be affected - but we will accept that as a constraint. The solution methodology remains the same though.
- Apply a learning algorithm on the feature-set to learn the driver behavior. Then the model needs to be deployed on a machine in the cloud. In real-time we need to calculate the same aggregates over the same time interval (15 seconds) and feed it into the model to come up with a prediction. To confirm the driver we will need to take readings over several intervals (5 minutes will give 20 predictions) and then use the value with the maximum count (i.e. modal value).
Augmenting raw data with derivatives
This is a very common scenario in IoT applications. When generated data comes from a human being, it always has useful information at the surface. All you need to do is scan the logs and extract it. An example of this is finding the interests of the user based on user-clicks in a shopping cart scenario - all the items that the user has seen on the web-site are directly found in the logs. However an IoT device is dumb, has no emotion, has no special interests. All data coming from an IoT device is the same consistent boring stream. So where do you dig to find useful information? The answer to this question is in the time-derivatives. The variation in values from one reading and the other provides useful insight into the behavior. Examples of these are velocity (derivative of displacement found from GPS readings), acceleration (derivative of velocity) and jerk (derivative of acceleration). So you see, augmenting raw data to put this extra information is extremely useful for IoT applications.
In this step I am going to write some Javascript code (that runs inside the MongoDB database) to augment raw data with derivatives for each record. You will find all this code in the file 'extract_driver_features_from_car_readings.js' which is located inside the 'machinelearning' folder. If you are wondering where to find the code, it is in Github at this location https://github.com/anupambagchi/driver-signature-raspberry-pi.
Processing raw records
Before diving into the code, let me clarify a few things. The code is written to run as a cronjob on a machine on the same network as the MongoDB database - so that it is accessible. Since it runs as a cron task, we need to know how many records to process from the raw data table. Thus we need to do some book-keeping on the database. We have a special collection called 'book_keeping' for this purpose where we store some book-keeping information. One of them is the last date till when we have processed the records. The data (in JSON format) may look like this:
{
"_id" : "processed_until",
"lastEndTime" : ISODate("2017-12-08T23:56:56.724+0000")
}
{
"_id" : "processed_until",
"lastEndTime" : ISODate("2017-12-08T23:56:56.724+0000")
}
To determine where we need to pick up the record processing from, here is one way to do this in a MongoDB script written in Javascript.
// Look up the book-keeping table to figure out the time from where we need to pick up
var processedUntil = db.getCollection('book_keeping').findOne( { _id: "processed_until" } );
endTime = new Date(); // Set the end time to the current time
if (processedUntil != null) {
startTime = processedUntil.lastEndTime;
} else {
db.book_keeping.insert( { _id: "processed_until", lastEndTime: endTime } );
startTime = new Date(endTime.getTime() - (365*86400000)); // Go back 365 days
}
// Look up the book-keeping table to figure out the time from where we need to pick up
var processedUntil = db.getCollection('book_keeping').findOne( { _id: "processed_until" } );
endTime = new Date(); // Set the end time to the current time
if (processedUntil != null) {
startTime = processedUntil.lastEndTime;
} else {
db.book_keeping.insert( { _id: "processed_until", lastEndTime: endTime } );
startTime = new Date(endTime.getTime() - (365*86400000)); // Go back 365 days
}
The 'else' part of the logic above is for the initialization phase when we run it for the first time - we just want to pick up all records for the past year.
Keeping track of driver vehicle combination
Another book-keeping task is to keep track of the driver-vehicle combinations. To make the job easier for the machine learning algorithm, this should be converted to indices. Those indices are maintained in the database in another book-keeping collection called 'driver_vehicles'. This collection looks somewhat like this:
{
"_id" : "driver_vehicles",
"drivers" : {
"gmc-denali-2015_jonathan" : 0.0,
"gmc-denali-2015_mindy" : 1.0,
"gmc-denali-2015_charles" : 2.0,
"gmc-denali-2015_chris" : 3.0,
"gmc-denali-2015_elise" : 4.0,
"gmc-denali-2015_thomas" : 5.0,
"toyota-camry-2009_alice" : 6.0,
"gmc-denali-2015_andrew" : 7.0,
"toyota-highlander-2005_arka" : 8.0,
"subaru-outback-2015_john" : 9.0,
"gmc-denali-2015_grant" : 10.0,
"gmc-denali-2015_avni" : 11.0,
"toyota-highlander-2005_anupam" : 12.0,
}
}
{
"_id" : "driver_vehicles",
"drivers" : {
"gmc-denali-2015_jonathan" : 0.0,
"gmc-denali-2015_mindy" : 1.0,
"gmc-denali-2015_charles" : 2.0,
"gmc-denali-2015_chris" : 3.0,
"gmc-denali-2015_elise" : 4.0,
"gmc-denali-2015_thomas" : 5.0,
"toyota-camry-2009_alice" : 6.0,
"gmc-denali-2015_andrew" : 7.0,
"toyota-highlander-2005_arka" : 8.0,
"subaru-outback-2015_john" : 9.0,
"gmc-denali-2015_grant" : 10.0,
"gmc-denali-2015_avni" : 11.0,
"toyota-highlander-2005_anupam" : 12.0,
}
}
These are the names of vehicles with their drivers. Each combination has been assigned a number against it. When a driver-vehicle combination is encountered, the program looks to see if that combination already exists or not. If not, then it adds a new combination. Here is the code to do it.
// Another book-keeping task is to read the driver-vehicle hash-table from the database
// Look up the book-keeping table to figure out the previous driver-vehicle codes (we have
// numbers representing the combination of drivers and vehicles).
var driverVehicles = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles" } );
var drivers;
if (driverVehicles != null)
drivers = driverVehicles.drivers;
else
drivers = {};
var maxDriverVehicleId = 0;
for (var key in drivers) {
if (drivers.hasOwnProperty(key)) {
maxDriverVehicleId = Math.max(maxDriverVehicleId, drivers[key]);
}
}
// Another book-keeping task is to read the driver-vehicle hash-table from the database
// Look up the book-keeping table to figure out the previous driver-vehicle codes (we have
// numbers representing the combination of drivers and vehicles).
var driverVehicles = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles" } );
var drivers;
if (driverVehicles != null)
drivers = driverVehicles.drivers;
else
drivers = {};
var maxDriverVehicleId = 0;
for (var key in drivers) {
if (drivers.hasOwnProperty(key)) {
maxDriverVehicleId = Math.max(maxDriverVehicleId, drivers[key]);
}
}
You can see that a 'find' call to the MongoDb database is being made to read the hash-table in memory.
The next task is to query the raw collection to find out which records are new since the last time it ran.
NOTE: In the code segments below the dollar symbol will show up as '@'. Please make the appropriate substitutions when you read it. The correct code may be found in the github repository.
// Now do a query of the database to find out what records are new since we ran it last
var allNewCarDrivers = db.getCollection('car_readings').aggregate([
{
"@match": {
"timestamp" : { @gt: startTimeStr, @lte: endTimeStr }
}
},
{
"@unwind": "@data"
},
{
"@group": { _id: "@data.username" }
}
]);
// Now do a query of the database to find out what records are new since we ran it last
var allNewCarDrivers = db.getCollection('car_readings').aggregate([
{
"@match": {
"timestamp" : { @gt: startTimeStr, @lte: endTimeStr }
}
},
{
"@unwind": "@data"
},
{
"@group": { _id: "@data.username" }
}
]);
SQL vs. Document-oriented database
The next part is the crux of the actual process happening in this script. To understand how this works you need to be familiar with the MongoDB aggregation framework. A task like this will take way too much code if you start writing SQL. Most relational databases and also Spark offer SQL as a way to process and aggregate their data. The most common reason I have heard from managers to take that approach is - "it is easy". That works, but it is too verbose. That is why I personally prefer to use the aggregation framework of MongoDB to do my pre-processing since I can operate much faster than the other tools out there. It may not be "easy" as per the common belief, but a bit more effort in studying the aggregation framework pays off - saving a lot of development effort.
What about execution time? These scripts execute on the database nodes - inside the database. Thus you cannot make it any faster - since most of the time spent in dealing with large data is in transporting the data from the storage nodes to the execution nodes. In the case of the aggregation frameworks, you are getting all benefits of BigData for free. You are actually using in-database analytics here for the fastest execution time.
// Look at all the records returned and process each driver one-by-one
// The following query is a pipeline with the following steps:
allNewCarDrivers.forEach(function(driverId) {
var driverName = driverId._id;
print("Processing driver: " + driverName);
var allNewCarReadings = db.getCollection('car_readings').aggregate([
{
"@match": { // 1. Match all records that fall within the time range we have decided to use. Note that this is being
// done on a live database - which means that new data is coming in while we are trying to analyze it.
// Thus we have to pin both the starting time and the ending time. Pinning the endtime to the starting time
// of the application ensures that we will be accurately picking up only the NEW records when the program
// runs again the next time.
"timestamp" : { @gt: startTimeStr, @lte: endTimeStr }
}
},
{
@project: { // We only need to consider a few fields for our analysis. This eliminates the summaries from our analysis.
"timestamp": 1,
"data" : 1,
"account": 1,
"_id": 0
}
},
{
@unwind: "@data" // Flatten out all records into one gigantic array of records
},
{
@match: {
"data.username": driverName // Only consider the records for this specific driver, ignoring all others.
}
},
{
@sort: {
"data.eventtime": 1 // Finally sort the data based on eventtime in ascending order
}
}
]);
// Look at all the records returned and process each driver one-by-one
// The following query is a pipeline with the following steps:
allNewCarDrivers.forEach(function(driverId) {
var driverName = driverId._id;
print("Processing driver: " + driverName);
var allNewCarReadings = db.getCollection('car_readings').aggregate([
{
"@match": { // 1. Match all records that fall within the time range we have decided to use. Note that this is being
// done on a live database - which means that new data is coming in while we are trying to analyze it.
// Thus we have to pin both the starting time and the ending time. Pinning the endtime to the starting time
// of the application ensures that we will be accurately picking up only the NEW records when the program
// runs again the next time.
"timestamp" : { @gt: startTimeStr, @lte: endTimeStr }
}
},
{
@project: { // We only need to consider a few fields for our analysis. This eliminates the summaries from our analysis.
"timestamp": 1,
"data" : 1,
"account": 1,
"_id": 0
}
},
{
@unwind: "@data" // Flatten out all records into one gigantic array of records
},
{
@match: {
"data.username": driverName // Only consider the records for this specific driver, ignoring all others.
}
},
{
@sort: {
"data.eventtime": 1 // Finally sort the data based on eventtime in ascending order
}
}
]);
This nifty script above does a lot of things. The first thing to note in this script is that we are operating on a live database that has a constant stream of data coming in. Thus in order to select some records for processing we need to decide the time range first and only select those that fall within that time range. The next time we run this script, the records that could not be picked up this time, will be gathered and processed. This is all being done within the 'match' clause.
The second clause is the 'project' clause - which only selects the four required fields for the next stage of the pipeline. The 'unwind' clause flattens all arrays. The next 'match' clause select the driver name and the final 'sort' clause sorts the data by eventtime in ascending order.
Distance on earth between two points
Before proceeding further, I would like to get one thing out of the way. Since we are dealing with a lot of latitude-longitude pairs and subsequently trying to find displacement, velocity and acceleration, we need a way to calculate the distance between two points on earth. There are several algorithms with varying degree of accuracy, but this is the one I have found to be computationally accurate (if you do not have an algorithm already provided by the database vendor).
function earth_distance_havesine(lat1, lon1, lat2, lon2, unit) {
var radius = 3959; // miles
var phi1 = lat1.toRadians();
var phi2 = lat2.toRadians();
var delphi = (lat2-lat1).toRadians();
var dellambda = (lon2-lon1).toRadians();
var a = Math.sin(delphi/2) * Math.sin(delphi/2) +
Math.cos(phi1) * Math.cos(phi2) *
Math.sin(dellambda/2) * Math.sin(dellambda/2);
var c = 2 * Math.atan2(Math.sqrt(a), Math.sqrt(1-a));
var dist = radius * c;
if (unit=="K") { dist = dist * 1.609344 }
if (unit=="N") { dist = dist * 0.8684 }
return dist;
}
function earth_distance_havesine(lat1, lon1, lat2, lon2, unit) {
var radius = 3959; // miles
var phi1 = lat1.toRadians();
var phi2 = lat2.toRadians();
var delphi = (lat2-lat1).toRadians();
var dellambda = (lon2-lon1).toRadians();
var a = Math.sin(delphi/2) * Math.sin(delphi/2) +
Math.cos(phi1) * Math.cos(phi2) *
Math.sin(dellambda/2) * Math.sin(dellambda/2);
var c = 2 * Math.atan2(Math.sqrt(a), Math.sqrt(1-a));
var dist = radius * c;
if (unit=="K") { dist = dist * 1.609344 }
if (unit=="N") { dist = dist * 0.8684 }
return dist;
}
We will be using this function in the next analysis. As I said before, our goal is to augment our device records with extra information pertaining to time-derivatives. The following code adds extra fields "interval", "acceleration", "angular_velocity" and "incline" to each device record by comparing it with the preceeding record.
var lastRecord = null; // We create a variable to remember what was the last record processed
var numProcessedRecords = 0;
allNewCarReadings.forEach(function(record) {
// Here we are reading a raw record from the car_readings collection, and then enhancing it with a few more
// variables. These are the (1) id of the driver-vehicle combination and (2) the delta values between current and previous record
numProcessedRecords += 1; // This is just for printing number of processed records when the program is running
var lastTime; // This is the timestamp of the last record
if (lastRecord !== null) {
lastTime = lastRecord.data.eventtime;
} else {
lastTime = "";
}
var eventTime = record.data.eventtime;
record.data.eventTimestamp = new Date(record.data.eventtime+'Z'); // Creating a real timestamp from an ISO string (without the trailing 'Z')
// print('Eventtime = ' + eventTime);
if (eventTime !== lastTime) { // this must be a new record
var driverVehicle = record.data.vehicle + "_" + record.data.username;
if (drivers.hasOwnProperty(driverVehicle))
record.driverVehicleId = drivers[driverVehicle];
else {
drivers[driverVehicle] = maxDriverVehicleId;
record.driverVehicleId = maxDriverVehicleId;
maxDriverVehicleId += 1;
}
record.delta = {}; // delta stores the difference between the current record and the previous record
if (lastRecord !== null) {
var timeDifference = record.data.eventTimestamp.getTime() - lastRecord.data.eventTimestamp.getTime(); // in milliseconds
record.delta["distance"] = earth_distance_havesine(
record.data.location.coordinates[1],
record.data.location.coordinates[0],
lastRecord.data.location.coordinates[1],
lastRecord.data.location.coordinates[0],
"K");
if (timeDifference < 60000) {
// if time difference is less than 60 seconds, only then can we consider it as part of the same session
// print(JSON.stringify(lastRecord.data));
record.delta["interval"] = timeDifference;
record.delta["acceleration"] = 1000 * (record.data.speed - lastRecord.data.speed) / timeDifference;
record.delta["angular_velocity"] = (record.data.heading - lastRecord.data.heading) / timeDifference;
record.delta["incline"] = (record.data.altitude - lastRecord.data.altitude) / timeDifference;
} else {
// otherwise this is a new session. So we still store the records, but the delta calculation is all set to zero.
record.delta["interval"] = timeDifference;
record.delta["acceleration"] = 0.0;
record.delta["angular_velocity"] = 0.0;
record.delta["incline"] = 0.0;
}
db.getCollection('mldataset').insert(record);
}
}
if (numProcessedRecords % 100 === 0)
print("Processed " + numProcessedRecords + " records");
lastRecord = record;
});
});
var lastRecord = null; // We create a variable to remember what was the last record processed
var numProcessedRecords = 0;
allNewCarReadings.forEach(function(record) {
// Here we are reading a raw record from the car_readings collection, and then enhancing it with a few more
// variables. These are the (1) id of the driver-vehicle combination and (2) the delta values between current and previous record
numProcessedRecords += 1; // This is just for printing number of processed records when the program is running
var lastTime; // This is the timestamp of the last record
if (lastRecord !== null) {
lastTime = lastRecord.data.eventtime;
} else {
lastTime = "";
}
var eventTime = record.data.eventtime;
record.data.eventTimestamp = new Date(record.data.eventtime+'Z'); // Creating a real timestamp from an ISO string (without the trailing 'Z')
// print('Eventtime = ' + eventTime);
if (eventTime !== lastTime) { // this must be a new record
var driverVehicle = record.data.vehicle + "_" + record.data.username;
if (drivers.hasOwnProperty(driverVehicle))
record.driverVehicleId = drivers[driverVehicle];
else {
drivers[driverVehicle] = maxDriverVehicleId;
record.driverVehicleId = maxDriverVehicleId;
maxDriverVehicleId += 1;
}
record.delta = {}; // delta stores the difference between the current record and the previous record
if (lastRecord !== null) {
var timeDifference = record.data.eventTimestamp.getTime() - lastRecord.data.eventTimestamp.getTime(); // in milliseconds
record.delta["distance"] = earth_distance_havesine(
record.data.location.coordinates[1],
record.data.location.coordinates[0],
lastRecord.data.location.coordinates[1],
lastRecord.data.location.coordinates[0],
"K");
if (timeDifference < 60000) {
// if time difference is less than 60 seconds, only then can we consider it as part of the same session
// print(JSON.stringify(lastRecord.data));
record.delta["interval"] = timeDifference;
record.delta["acceleration"] = 1000 * (record.data.speed - lastRecord.data.speed) / timeDifference;
record.delta["angular_velocity"] = (record.data.heading - lastRecord.data.heading) / timeDifference;
record.delta["incline"] = (record.data.altitude - lastRecord.data.altitude) / timeDifference;
} else {
// otherwise this is a new session. So we still store the records, but the delta calculation is all set to zero.
record.delta["interval"] = timeDifference;
record.delta["acceleration"] = 0.0;
record.delta["angular_velocity"] = 0.0;
record.delta["incline"] = 0.0;
}
db.getCollection('mldataset').insert(record);
}
}
if (numProcessedRecords % 100 === 0)
print("Processed " + numProcessedRecords + " records");
lastRecord = record;
});
});
Note that in line 50, I am saving the record in another collection called 'mldataset' which is going to be the collection on which I will apply feature-extraction for driver signatures. The final task is to save the book-keeping values in their respective tables.
db.book_keeping.update(
{ _id: "driver_vehicles"},
{ \(set: { drivers: drivers } },
{ upsert: true }
);
// Save the end time to the database
db.book_keeping.update(
{ _id: "processed_until" },
{ \)set: { lastEndTime: endTime } },
{ upsert: true }
);
db.book_keeping.update(
{ _id: "driver_vehicles"},
{ \(set: { drivers: drivers } },
{ upsert: true }
);
// Save the end time to the database
db.book_keeping.update(
{ _id: "processed_until" },
{ \)set: { lastEndTime: endTime } },
{ upsert: true }
);
Creating the feature set for driver signatures
The next step is to create the feature sets for driver signature analysis. I do this by first reading records from the augmented collection 'mldataset' and aggregating values over every 15 minutes. For each field that contains a number (and it happens to change often), I will calculate three statistical values for each field - the minimum over the time window, the maximum and the average. Interestingly, one can also include other statistical values like variance, kertosis - but I have not tried those in my experiment yet - and is an enhancement that you can do easily.
You will find all the code in the file 'extract_features_from_mldataset.js' under the 'machinelearning' directory.
Let us do some book-keeping first.
var processedUntil = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles_processed_until" } );
var currentTime = new Date(); // This time includes the seconds value
// Set the end time (for querying) to the current time till the last whole minute, excluding seconds
var endTimeGlobal = new Date(Date.UTC(currentTime.getFullYear(), currentTime.getMonth(), currentTime.getDate(), currentTime.getHours(), currentTime.getMinutes(), 0, 0))
if (processedUntil === null) {
db.book_keeping.insert( { _id: "driver_vehicles_processed_until", lastEndTimes: [] } ); // initialize to an empty array
}
// Now do a query of the database to find out what records are new since we ran it last
var startTimeForSearchingActiveDevices = new Date(endTimeGlobal.getTime() - (200*86400000)); // Go back 200 days
// Another book-keeping task is to read the driver-vehicle hash-table from the database.
// Look up the book-keeping table to figure out the previous driver-vehicle codes (we have
// numbers representing the combination of drivers and vehicles).
var driverVehicles = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles" } );
var drivers;
if (driverVehicles !== null)
drivers = driverVehicles.drivers;
else
drivers = {};
var maxDriverVehicleId = 0;
for (var key in drivers) {
if (drivers.hasOwnProperty(key)) {
maxDriverVehicleId = Math.max(maxDriverVehicleId, drivers[key]);
}
}
var processedUntil = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles_processed_until" } );
var currentTime = new Date(); // This time includes the seconds value
// Set the end time (for querying) to the current time till the last whole minute, excluding seconds
var endTimeGlobal = new Date(Date.UTC(currentTime.getFullYear(), currentTime.getMonth(), currentTime.getDate(), currentTime.getHours(), currentTime.getMinutes(), 0, 0))
if (processedUntil === null) {
db.book_keeping.insert( { _id: "driver_vehicles_processed_until", lastEndTimes: [] } ); // initialize to an empty array
}
// Now do a query of the database to find out what records are new since we ran it last
var startTimeForSearchingActiveDevices = new Date(endTimeGlobal.getTime() - (200*86400000)); // Go back 200 days
// Another book-keeping task is to read the driver-vehicle hash-table from the database.
// Look up the book-keeping table to figure out the previous driver-vehicle codes (we have
// numbers representing the combination of drivers and vehicles).
var driverVehicles = db.getCollection('book_keeping').findOne( { _id: "driver_vehicles" } );
var drivers;
if (driverVehicles !== null)
drivers = driverVehicles.drivers;
else
drivers = {};
var maxDriverVehicleId = 0;
for (var key in drivers) {
if (drivers.hasOwnProperty(key)) {
maxDriverVehicleId = Math.max(maxDriverVehicleId, drivers[key]);
}
}
Using the last time stamp stored in the system, we can figure out which records are new.
// Now do a query of the database to find out what records are new since we ran it last
var allNewCarDrivers = db.getCollection('mldataset').aggregate([
{
"@match": {
"data.eventTimestamp" : { @gt: startTimeForSearchingActiveDevices, @lte: endTimeGlobal }
}
},
{
"@group": { _id: "@data.username" }
}
]);
// Now do a query of the database to find out what records are new since we ran it last
var allNewCarDrivers = db.getCollection('mldataset').aggregate([
{
"@match": {
"data.eventTimestamp" : { @gt: startTimeForSearchingActiveDevices, @lte: endTimeGlobal }
}
},
{
"@group": { _id: "@data.username" }
}
]);
Extracting features for each driver
Now is the time to do the actual feature extraction from the data-set. Here is the entire loop:
allNewCarDrivers.forEach(function(driverId) {
var driverName = driverId._id;
print("Processing driver: " + driverName);
var startTimeForDriver = startTimeForSearchingActiveDevices; // To begin with we start with the earliest start time we care about
var driverIsNew = true;
// First find out if this device already has some records processed, and has a last end time defined
var lastEndTimeDevice = db.getCollection('book_keeping').find(
{
_id: "driver_vehicles_processed_until",
"lastEndTimes.driver": driverName
},
{
_id: 0,
'lastEndTimes.@': 1
}
);
lastEndTimeDevice.forEach(function(record) {
startTimeForDriver = record.lastEndTimes[0].endTime;
driverIsNew = false;
});
//print('Starting time for driver is ' + startTimeForDriver.toISOString());
//print('endTimeGlobal = ' + endTimeGlobal.toISOString());
var allNewCarReadings = db.getCollection('mldataset').aggregate([
{
"@match": { // 1. Match all records that fall within the time range we have decided to use. Note that this is being
// done on a live database - which means that new data is coming in while we are trying to analyze it.
// Thus we have to pin both the starting time and the ending time. Pinning the endtime to the starting time
// of the application ensures that we will be accurately picking up only the NEW records when the program
// runs again the next time.
"data.eventTimestamp": {@gt: startTimeForDriver, @lte: endTimeGlobal},
"data.username": driverName // Only consider the records for this specific driver, ignoring all others.
}
},
{
@project: { // We only need to consider a few fields for our analysis. This eliminates the summaries from our analysis.
"data": 1,
"account": 1,
"delta": 1,
"driverVehicleId": 1,
"_id": 0
}
},
{
"@group": {
"_id": {
year: {@year: "@data.eventTimestamp"},
month: {@month: "@data.eventTimestamp"},
day: {@dayOfMonth: "@data.eventTimestamp"},
hour: {@hour: "@data.eventTimestamp"},
minute: {@minute: "@data.eventTimestamp"},
quarter: {@mod: [{@second: "@data.eventTimestamp"}, 4]}
},
"averageGPSLatitude": {@avg: {"@arrayElemAt": ["@data.location.coordinates", 1]}},
"averageGPSLongitude": {@avg: {"@arrayElemAt": ["@data.location.coordinates", 0]}},
"averageLoad": {@avg: "@data.load"},
"minLoad": {@min: "@data.load"},
"maxLoad": {@max: "@data.load"},
"averageThrottlePosB": {@avg: "@data.abs_throttle_pos_b"},
"minThrottlePosB": {@min: "@data.abs_throttle_pos_b"},
"maxThrottlePosB": {@max: "@data.abs_throttle_pos_b"},
"averageRpm": {@avg: "@data.rpm"},
"minRpm": {@min: "@data.rpm"},
"maxRpm": {@max: "@data.rpm"},
"averageThrottlePos": {@avg: "@data.throttle_pos"},
"minThrottlePos": {@min: "@data.throttle_pos"},
"maxThrottlePos": {@max: "@data.throttle_pos"},
"averageIntakeAirTemp": {@avg: "@data.intake_air_temp"},
"minIntakeAirTemp": {@min: "@data.intake_air_temp"},
"maxIntakeAirTemp": {@max: "@data.intake_air_temp"},
"averageSpeed": {@avg: "@data.speed"},
"minSpeed": {@min: "@data.speed"},
"maxSpeed": {@max: "@data.speed"},
"averageAltitude": {@avg: "@data.altitude"},
"minAltitude": {@min: "@data.altitude"},
"maxAltitude": {@max: "@data.altitude"},
"averageCommThrottleAc": {@avg: "@data.comm_throttle_ac"},
"minCommThrottleAc": {@min: "@data.comm_throttle_ac"},
"maxCommThrottleAc": {@max: "@data.comm_throttle_ac"},
"averageEngineTime": {@avg: "@data.engine_time"},
"minEngineTime": {@min: "@data.engine_time"},
"maxEngineTime": {@max: "@data.engine_time"},
"averageAbsLoad": {@avg: "@data.abs_load"},
"minAbsLoad": {@min: "@data.abs_load"},
"maxAbsLoad": {@max: "@data.abs_load"},
"averageGear": {@avg: "@data.gear"},
"minGear": {@min: "@data.gear"},
"maxGear": {@max: "@data.gear"},
"averageRelThrottlePos": {@avg: "@data.rel_throttle_pos"},
"minRelThrottlePos": {@min: "@data.rel_throttle_pos"},
"maxRelThrottlePos": {@max: "@data.rel_throttle_pos"},
"averageAccPedalPosE": {@avg: "@data.acc_pedal_pos_e"},
"minAccPedalPosE": {@min: "@data.acc_pedal_pos_e"},
"maxAccPedalPosE": {@max: "@data.acc_pedal_pos_e"},
"averageAccPedalPosD": {@avg: "@data.acc_pedal_pos_d"},
"minAccPedalPosD": {@min: "@data.acc_pedal_pos_d"},
"maxAccPedalPosD": {@max: "@data.acc_pedal_pos_d"},
"averageGpsSpeed": {@avg: "@data.gps_speed"},
"minGpsSpeed": {@min: "@data.gps_speed"},
"maxGpsSpeed": {@max: "@data.gps_speed"},
"averageShortTermFuelTrim2": {@avg: "@data.short_term_fuel_trim_2"},
"minShortTermFuelTrim2": {@min: "@data.short_term_fuel_trim_2"},
"maxShortTermFuelTrim2": {@max: "@data.short_term_fuel_trim_2"},
"averageO211": {@avg: "@data.o211"},
"minO211": {@min: "@data.o211"},
"maxO211": {@max: "@data.o211"},
"averageO212": {@avg: "@data.o212"},
"minO212": {@min: "@data.o212"},
"maxO212": {@max: "@data.o212"},
"averageShortTermFuelTrim1": {@avg: "@data.short_term_fuel_trim_1"},
"minShortTermFuelTrim1": {@min: "@data.short_term_fuel_trim_1"},
"maxShortTermFuelTrim1": {@max: "@data.short_term_fuel_trim_1"},
"averageMaf": {@avg: "@data.maf"},
"minMaf": {@min: "@data.maf"},
"maxMaf": {@max: "@data.maf"},
"averageTimingAdvance": {@avg: "@data.timing_advance"},
"minTimingAdvance": {@min: "@data.timing_advance"},
"maxTimingAdvance": {@max: "@data.timing_advance"},
"averageClimb": {@avg: "@data.climb"},
"minClimb": {@min: "@data.climb"},
"maxClimb": {@max: "@data.climb"},
"averageFuelPressure": {@avg: "@data.fuel_pressure"},
"minFuelPressure": {@min: "@data.fuel_pressure"},
"maxFuelPressure": {@max: "@data.fuel_pressure"},
"averageTemp": {@avg: "@data.temp"},
"minTemp": {@min: "@data.temp"},
"maxTemp": {@max: "@data.temp"},
"averageAmbientAirTemp": {@avg: "@data.ambient_air_temp"},
"minAmbientAirTemp": {@min: "@data.ambient_air_temp"},
"maxAmbientAirTemp": {@max: "@data.ambient_air_temp"},
"averageManifoldPressure": {@avg: "@data.manifold_pressure"},
"minManifoldPressure": {@min: "@data.manifold_pressure"},
"maxManifoldPressure": {@max: "@data.manifold_pressure"},
"averageLongTermFuelTrim1": {@avg: "@data.long_term_fuel_trim_1"},
"minLongTermFuelTrim1": {@min: "@data.long_term_fuel_trim_1"},
"maxLongTermFuelTrim1": {@max: "@data.long_term_fuel_trim_1"},
"averageLongTermFuelTrim2": {@avg: "@data.long_term_fuel_trim_2"},
"minLongTermFuelTrim2": {@min: "@data.long_term_fuel_trim_2"},
"maxLongTermFuelTrim2": {@max: "@data.long_term_fuel_trim_2"},
"averageGPSAcceleration": {@avg: "@delta.acceleration"},
"minGPSAcceleration": {@min: "@delta.acceleration"},
"maxGPSAcceleration": {@max: "@delta.acceleration"},
"averageHeadingChange": {@avg: {@abs: "@delta.angular_velocity"}},
"minHeadingChange": {@min: {@abs: "@delta.angular_velocity"}},
"maxHeadingChange": {@max: {@abs: "@delta.angular_velocity"}},
"averageIncline": {@avg: "@data.incline"},
"minIncline": {@min: "@data.incline"},
"maxIncline": {@max: "@data.incline"},
"averageAcceleration": {@avg: "@delta.acceleration"},
"minAcceleration": {@min: "@delta.acceleration"},
"maxAcceleration": {@max: "@delta.acceleration"},
// "dtcCodes": {"@push": "@data.dtc_status"},
"accountIdArray": {@addToSet: "@account"},
"vehicleArray": {@addToSet: "@data.vehicle"},
"driverArray": {@addToSet: "@data.username"},
"driverVehicleArray": {@addToSet: "@driverVehicleId"},
"count": {@sum: 1}
}
},
{
@sort: {
"_id": 1 // Finally sort the data based on eventtime in ascending order
}
}
],
{
allowDiskUse: true
}
);
allNewCarDrivers.forEach(function(driverId) {
var driverName = driverId._id;
print("Processing driver: " + driverName);
var startTimeForDriver = startTimeForSearchingActiveDevices; // To begin with we start with the earliest start time we care about
var driverIsNew = true;
// First find out if this device already has some records processed, and has a last end time defined
var lastEndTimeDevice = db.getCollection('book_keeping').find(
{
_id: "driver_vehicles_processed_until",
"lastEndTimes.driver": driverName
},
{
_id: 0,
'lastEndTimes.@': 1
}
);
lastEndTimeDevice.forEach(function(record) {
startTimeForDriver = record.lastEndTimes[0].endTime;
driverIsNew = false;
});
//print('Starting time for driver is ' + startTimeForDriver.toISOString());
//print('endTimeGlobal = ' + endTimeGlobal.toISOString());
var allNewCarReadings = db.getCollection('mldataset').aggregate([
{
"@match": { // 1. Match all records that fall within the time range we have decided to use. Note that this is being
// done on a live database - which means that new data is coming in while we are trying to analyze it.
// Thus we have to pin both the starting time and the ending time. Pinning the endtime to the starting time
// of the application ensures that we will be accurately picking up only the NEW records when the program
// runs again the next time.
"data.eventTimestamp": {@gt: startTimeForDriver, @lte: endTimeGlobal},
"data.username": driverName // Only consider the records for this specific driver, ignoring all others.
}
},
{
@project: { // We only need to consider a few fields for our analysis. This eliminates the summaries from our analysis.
"data": 1,
"account": 1,
"delta": 1,
"driverVehicleId": 1,
"_id": 0
}
},
{
"@group": {
"_id": {
year: {@year: "@data.eventTimestamp"},
month: {@month: "@data.eventTimestamp"},
day: {@dayOfMonth: "@data.eventTimestamp"},
hour: {@hour: "@data.eventTimestamp"},
minute: {@minute: "@data.eventTimestamp"},
quarter: {@mod: [{@second: "@data.eventTimestamp"}, 4]}
},
"averageGPSLatitude": {@avg: {"@arrayElemAt": ["@data.location.coordinates", 1]}},
"averageGPSLongitude": {@avg: {"@arrayElemAt": ["@data.location.coordinates", 0]}},
"averageLoad": {@avg: "@data.load"},
"minLoad": {@min: "@data.load"},
"maxLoad": {@max: "@data.load"},
"averageThrottlePosB": {@avg: "@data.abs_throttle_pos_b"},
"minThrottlePosB": {@min: "@data.abs_throttle_pos_b"},
"maxThrottlePosB": {@max: "@data.abs_throttle_pos_b"},
"averageRpm": {@avg: "@data.rpm"},
"minRpm": {@min: "@data.rpm"},
"maxRpm": {@max: "@data.rpm"},
"averageThrottlePos": {@avg: "@data.throttle_pos"},
"minThrottlePos": {@min: "@data.throttle_pos"},
"maxThrottlePos": {@max: "@data.throttle_pos"},
"averageIntakeAirTemp": {@avg: "@data.intake_air_temp"},
"minIntakeAirTemp": {@min: "@data.intake_air_temp"},
"maxIntakeAirTemp": {@max: "@data.intake_air_temp"},
"averageSpeed": {@avg: "@data.speed"},
"minSpeed": {@min: "@data.speed"},
"maxSpeed": {@max: "@data.speed"},
"averageAltitude": {@avg: "@data.altitude"},
"minAltitude": {@min: "@data.altitude"},
"maxAltitude": {@max: "@data.altitude"},
"averageCommThrottleAc": {@avg: "@data.comm_throttle_ac"},
"minCommThrottleAc": {@min: "@data.comm_throttle_ac"},
"maxCommThrottleAc": {@max: "@data.comm_throttle_ac"},
"averageEngineTime": {@avg: "@data.engine_time"},
"minEngineTime": {@min: "@data.engine_time"},
"maxEngineTime": {@max: "@data.engine_time"},
"averageAbsLoad": {@avg: "@data.abs_load"},
"minAbsLoad": {@min: "@data.abs_load"},
"maxAbsLoad": {@max: "@data.abs_load"},
"averageGear": {@avg: "@data.gear"},
"minGear": {@min: "@data.gear"},
"maxGear": {@max: "@data.gear"},
"averageRelThrottlePos": {@avg: "@data.rel_throttle_pos"},
"minRelThrottlePos": {@min: "@data.rel_throttle_pos"},
"maxRelThrottlePos": {@max: "@data.rel_throttle_pos"},
"averageAccPedalPosE": {@avg: "@data.acc_pedal_pos_e"},
"minAccPedalPosE": {@min: "@data.acc_pedal_pos_e"},
"maxAccPedalPosE": {@max: "@data.acc_pedal_pos_e"},
"averageAccPedalPosD": {@avg: "@data.acc_pedal_pos_d"},
"minAccPedalPosD": {@min: "@data.acc_pedal_pos_d"},
"maxAccPedalPosD": {@max: "@data.acc_pedal_pos_d"},
"averageGpsSpeed": {@avg: "@data.gps_speed"},
"minGpsSpeed": {@min: "@data.gps_speed"},
"maxGpsSpeed": {@max: "@data.gps_speed"},
"averageShortTermFuelTrim2": {@avg: "@data.short_term_fuel_trim_2"},
"minShortTermFuelTrim2": {@min: "@data.short_term_fuel_trim_2"},
"maxShortTermFuelTrim2": {@max: "@data.short_term_fuel_trim_2"},
"averageO211": {@avg: "@data.o211"},
"minO211": {@min: "@data.o211"},
"maxO211": {@max: "@data.o211"},
"averageO212": {@avg: "@data.o212"},
"minO212": {@min: "@data.o212"},
"maxO212": {@max: "@data.o212"},
"averageShortTermFuelTrim1": {@avg: "@data.short_term_fuel_trim_1"},
"minShortTermFuelTrim1": {@min: "@data.short_term_fuel_trim_1"},
"maxShortTermFuelTrim1": {@max: "@data.short_term_fuel_trim_1"},
"averageMaf": {@avg: "@data.maf"},
"minMaf": {@min: "@data.maf"},
"maxMaf": {@max: "@data.maf"},
"averageTimingAdvance": {@avg: "@data.timing_advance"},
"minTimingAdvance": {@min: "@data.timing_advance"},
"maxTimingAdvance": {@max: "@data.timing_advance"},
"averageClimb": {@avg: "@data.climb"},
"minClimb": {@min: "@data.climb"},
"maxClimb": {@max: "@data.climb"},
"averageFuelPressure": {@avg: "@data.fuel_pressure"},
"minFuelPressure": {@min: "@data.fuel_pressure"},
"maxFuelPressure": {@max: "@data.fuel_pressure"},
"averageTemp": {@avg: "@data.temp"},
"minTemp": {@min: "@data.temp"},
"maxTemp": {@max: "@data.temp"},
"averageAmbientAirTemp": {@avg: "@data.ambient_air_temp"},
"minAmbientAirTemp": {@min: "@data.ambient_air_temp"},
"maxAmbientAirTemp": {@max: "@data.ambient_air_temp"},
"averageManifoldPressure": {@avg: "@data.manifold_pressure"},
"minManifoldPressure": {@min: "@data.manifold_pressure"},
"maxManifoldPressure": {@max: "@data.manifold_pressure"},
"averageLongTermFuelTrim1": {@avg: "@data.long_term_fuel_trim_1"},
"minLongTermFuelTrim1": {@min: "@data.long_term_fuel_trim_1"},
"maxLongTermFuelTrim1": {@max: "@data.long_term_fuel_trim_1"},
"averageLongTermFuelTrim2": {@avg: "@data.long_term_fuel_trim_2"},
"minLongTermFuelTrim2": {@min: "@data.long_term_fuel_trim_2"},
"maxLongTermFuelTrim2": {@max: "@data.long_term_fuel_trim_2"},
"averageGPSAcceleration": {@avg: "@delta.acceleration"},
"minGPSAcceleration": {@min: "@delta.acceleration"},
"maxGPSAcceleration": {@max: "@delta.acceleration"},
"averageHeadingChange": {@avg: {@abs: "@delta.angular_velocity"}},
"minHeadingChange": {@min: {@abs: "@delta.angular_velocity"}},
"maxHeadingChange": {@max: {@abs: "@delta.angular_velocity"}},
"averageIncline": {@avg: "@data.incline"},
"minIncline": {@min: "@data.incline"},
"maxIncline": {@max: "@data.incline"},
"averageAcceleration": {@avg: "@delta.acceleration"},
"minAcceleration": {@min: "@delta.acceleration"},
"maxAcceleration": {@max: "@delta.acceleration"},
// "dtcCodes": {"@push": "@data.dtc_status"},
"accountIdArray": {@addToSet: "@account"},
"vehicleArray": {@addToSet: "@data.vehicle"},
"driverArray": {@addToSet: "@data.username"},
"driverVehicleArray": {@addToSet: "@driverVehicleId"},
"count": {@sum: 1}
}
},
{
@sort: {
"_id": 1 // Finally sort the data based on eventtime in ascending order
}
}
],
{
allowDiskUse: true
}
);
For each driver (or rather driver-vehicle combination) that is identified, the first task is to figure out the last processing time for that driver and find all new records (lines 6 to 22). The next task of aggregating over 15 second windows is a MongoDB aggregation step starting from line 27. Aggregation tasks in MongoDB are described as pipeline where element element of the flow does a certain task and passes on the result to the next element in the pipe. The first task is to match all records within the time-span that we want to process (lines 29 to 36). Then we only need to consider (i.e. project) few fields that are of interest to us (lines 38 to 44). The element of the pipeline '\(group') does the actual job of aggregation. The key to this aggregation step is the group-by Id that is created using a 'quarter' (line 55) which is nothing but a number between 0 and 3 created out of the second value of the time-stamp. This effectively creates the time windows needed for aggregation.
The actual aggregation steps are quite repetitive. See for example lines 61 to 63 where the average load, minimum load and maximum load is being calculated based on the aggregate over each time period. This is repeated for all the variables that we want to consider in the feature-set. Before storing it, the values are sorted based on event-time (lines 200 to 202).
Saving the feature-set in a collection
The features thus calculated are saved to a new collection on which I would apply a machine-learning algorithm to create a model. The collection is called 'vehicle_signature_records' - where the feature-set records can be saved as follows:
var lastRecordedTimeForDriver = startTimeForDriver;
var insertCounter = 0;
allNewCarReadings.forEach(function (record) {
var currentRecordEventTime = new Date(Date.UTC(record._id.year, record._id.month - 1, record._id.day, record._id.hour, record._id.minute, record._id.quarter * 15, 0));
if (currentRecordEventTime >= lastRecordedTimeForDriver)
lastRecordedTimeForDriver = new Date(Date.UTC(record._id.year, record._id.month - 1, record._id.day, record._id.hour, record._id.minute, 59, 999));
record['eventTime'] = currentRecordEventTime;
record['eventId'] = record._id;
delete record._id;
record['accountId'] = record.accountIdArray[0];
delete record.accountIdArray;
record['vehicle'] = record.vehicleArray[0];
delete record.vehicleArray;
record['driver'] = record.driverArray[0];
delete record.driverArray;
record['driverVehicle'] = record.driverVehicleArray[0];
delete record.driverVehicleArray;
record.averageGPSLatitude = parseInt((record.averageGPSLatitude * 1000).toFixed(3)) / 1000;
record.averageGPSLongitude = parseInt((record.averageGPSLongitude * 1000).toFixed(3)) / 1000;
db.getCollection('vehicle_signature_records').insert(record);
insertCounter += 1;
});
var lastRecordedTimeForDriver = startTimeForDriver;
var insertCounter = 0;
allNewCarReadings.forEach(function (record) {
var currentRecordEventTime = new Date(Date.UTC(record._id.year, record._id.month - 1, record._id.day, record._id.hour, record._id.minute, record._id.quarter * 15, 0));
if (currentRecordEventTime >= lastRecordedTimeForDriver)
lastRecordedTimeForDriver = new Date(Date.UTC(record._id.year, record._id.month - 1, record._id.day, record._id.hour, record._id.minute, 59, 999));
record['eventTime'] = currentRecordEventTime;
record['eventId'] = record._id;
delete record._id;
record['accountId'] = record.accountIdArray[0];
delete record.accountIdArray;
record['vehicle'] = record.vehicleArray[0];
delete record.vehicleArray;
record['driver'] = record.driverArray[0];
delete record.driverArray;
record['driverVehicle'] = record.driverVehicleArray[0];
delete record.driverVehicleArray;
record.averageGPSLatitude = parseInt((record.averageGPSLatitude * 1000).toFixed(3)) / 1000;
record.averageGPSLongitude = parseInt((record.averageGPSLongitude * 1000).toFixed(3)) / 1000;
db.getCollection('vehicle_signature_records').insert(record);
insertCounter += 1;
});
The code above inserts a few more variables to identify the driver, the vehicle and the driver-vehicle combination to the result sent by the aggregation function (lines 8 to 21) and saves it to the database (line 26). However lines 23 and 24 need an explanation since it signifies something very important and significant!
Coding the approximate location of the driver
One of the interesting observations I discovered while working on this problem is that one can dramatically improve accuracy of prediction if you can code the approximate location of the driver. Imagine working on this problem for millions of drivers who are scattered all across the country. One of the important facts to consider is that most drivers generally drive around a certain location most of the time. Thus if their location is somehow encoded into the model, the model can quickly converge based on their location. Lines 23 and 24 attempt to do just that. It encodes two numbers that represent the approximate latitude and longitude of the location. All these lines do is store the latitude and longitude with reduced accuracy.
Some more book-keeping
As a final step the final task is to store the book-keeping values.
if (driverIsNew) { // which means this is a new device with no record
db.book_keeping.update(
{_id: 'driver_vehicles_processed_until'},
{@push: {'lastEndTimes': {driver: driverName, endTime: lastRecordedTimeForDriver}}}
);
} else {
var nowDate = new Date();
db.book_keeping.update(
{_id: 'driver_vehicles_processed_until', 'lastEndTimes.driver': driverName},
{@set: {'lastEndTimes.@.endTime': lastRecordedTimeForDriver, 'lastEndTimes.@.driver': driverName}} // lastRecordedTimeForDriver
);
}
if (driverIsNew) { // which means this is a new device with no record
db.book_keeping.update(
{_id: 'driver_vehicles_processed_until'},
{@push: {'lastEndTimes': {driver: driverName, endTime: lastRecordedTimeForDriver}}}
);
} else {
var nowDate = new Date();
db.book_keeping.update(
{_id: 'driver_vehicles_processed_until', 'lastEndTimes.driver': driverName},
{@set: {'lastEndTimes.@.endTime': lastRecordedTimeForDriver, 'lastEndTimes.@.driver': driverName}} // lastRecordedTimeForDriver
);
}
After doing all this work (which by now you may be already exhausted after reading through), we are finally ready to apply some real machine-learning algorithms. Remember, I said before that 95% of the task of a data scientist is in preparing, collecting, consolidating and cleaning the data. You are seeing a live example of that!
In big companies there are people called data-engineers who would do part of this job, but not all people are fortunate enough to have data-engineers working for them. Besides, if you can do all this work, you are more indispensible to the company you work for - and so it makes sense to develop these skills along with your analysis skills as a data-scientist.
Building a Machine Learning Model
Fortunately, the data has been created in a clean way, so there is no further clean-up required on it. Our data is in a MongoDB collection called 'vehicle_signature_records'. If you are a pure Data Scientist the following should be very familar to you. The only difference between what I am going to do now and what you generally find in books and blogs, is the data-source. I am going to read my data-sets directly from the MongoDB database instead of from CSV files. After reading the above, by now you must have become partial experts at understanding MongoDB document structures. If not, don't worry since all the data that we stored in the collection are all flat - i.e. all values are present at the top level of each record. To illlustrate how the data looks, let me show you one record from the collection.
{
"_id" : ObjectId("5a3028db7984b918e715c2a7"),
"averageGPSLatitude" : 37.386,
"averageGPSLongitude" : -121.96,
"averageLoad" : 24.80392156862745,
"minLoad" : 0.0,
"maxLoad" : 68.62745098039215,
"averageThrottlePosB" : 29.11764705882353,
"minThrottlePosB" : 14.901960784313726,
"maxThrottlePosB" : 38.03921568627451,
"averageRpm" : 1216.25,
"minRpm" : 516.0,
"maxRpm" : 1486.0,
"averageThrottlePos" : 20.49019607843137,
"minThrottlePos" : 11.764705882352942,
"maxThrottlePos" : 36.86274509803921,
"averageIntakeAirTemp" : 85.5,
"minIntakeAirTemp" : 84.0,
"maxIntakeAirTemp" : 86.0,
"averageSpeed" : 13.517712865133625,
"minSpeed" : 0.0,
"maxSpeed" : 24.238657551274084,
"averageAltitude" : -1.575,
"minAltitude" : -1.9,
"maxAltitude" : -1.2,
"averageCommThrottleAc" : 25.392156862745097,
"minCommThrottleAc" : 6.2745098039215685,
"maxCommThrottleAc" : 38.431372549019606,
"averageEngineTime" : 32.25,
"minEngineTime" : 32.0,
"maxEngineTime" : 33.0,
"averageAbsLoad" : 40.3921568627451,
"minAbsLoad" : 18.431372549019606,
"maxAbsLoad" : 64.31372549019608,
"averageGear" : 0.0,
"minGear" : 0.0,
"maxGear" : 0.0,
"averageRelThrottlePos" : 19.019607843137255,
"minRelThrottlePos" : 4.705882352941177,
"maxRelThrottlePos" : 27.84313725490196,
"averageAccPedalPosE" : 14.607843137254902,
"minAccPedalPosE" : 9.411764705882353,
"maxAccPedalPosE" : 19.215686274509803,
"averageAccPedalPosD" : 30.19607843137255,
"minAccPedalPosD" : 18.823529411764707,
"maxAccPedalPosD" : 39.21568627450981,
"averageGpsSpeed" : 6.720000000000001,
"minGpsSpeed" : 0.0,
"maxGpsSpeed" : 12.82,
"averageShortTermFuelTrim2" : -0.5,
"minShortTermFuelTrim2" : -1.0,
"maxShortTermFuelTrim2" : 1.0,
"averageO211" : 9698.5,
"minO211" : 1191.0,
"maxO211" : 27000.0,
"averageO212" : 30349.0,
"minO212" : 28299.0,
"maxO212" : 32499.0,
"averageShortTermFuelTrim1" : -0.25,
"minShortTermFuelTrim1" : -2.0,
"maxShortTermFuelTrim1" : 4.0,
"averageMaf" : 2.4332170200000003,
"minMaf" : 0.77513736,
"maxMaf" : 7.0106280000000005,
"averageTimingAdvance" : 28.0,
"minTimingAdvance" : 16.5,
"maxTimingAdvance" : 41.0,
"averageClimb" : -0.025,
"minClimb" : -0.2,
"maxClimb" : 0.1,
"averageFuelPressure" : null,
"minFuelPressure" : null,
"maxFuelPressure" : null,
"averageTemp" : 199.0,
"minTemp" : 199.0,
"maxTemp" : 199.0,
"averageAmbientAirTemp" : 77.75,
"minAmbientAirTemp" : 77.0,
"maxAmbientAirTemp" : 78.0,
"averageManifoldPressure" : 415.4026475455047,
"minManifoldPressure" : 248.2073910645339,
"maxManifoldPressure" : 592.9398786541643,
"averageLongTermFuelTrim1" : 3.25,
"minLongTermFuelTrim1" : -1.0,
"maxLongTermFuelTrim1" : 7.0,
"averageLongTermFuelTrim2" : -23.5,
"minLongTermFuelTrim2" : -100.0,
"maxLongTermFuelTrim2" : 7.0,
"averageGPSAcceleration" : 1.0196509034930195,
"minGPSAcceleration" : 0.0,
"maxGPSAcceleration" : 1.9128551867763974,
"averageHeadingChange" : 0.006215710862578118,
"minHeadingChange" : 0.0,
"maxHeadingChange" : 0.013477895914941244,
"averageIncline" : null,
"minIncline" : null,
"maxIncline" : null,
"averageAcceleration" : 1.0196509034930195,
"minAcceleration" : 0.0,
"maxAcceleration" : 1.9128551867763974,
"count" : 4.0,
"eventTime" : ISODate("2017-07-18T18:11:30.000+0000"),
"eventId" : {
"year" : NumberInt(2017),
"month" : NumberInt(7),
"day" : NumberInt(18),
"hour" : NumberInt(18),
"minute" : NumberInt(11),
"quarter" : NumberInt(2)
},
"accountId" : "17350",
"vehicle" : "toyota-highlander-2005",
"driver" : "anupam",
"driverVehicle" : 12.0
}
{
"_id" : ObjectId("5a3028db7984b918e715c2a7"),
"averageGPSLatitude" : 37.386,
"averageGPSLongitude" : -121.96,
"averageLoad" : 24.80392156862745,
"minLoad" : 0.0,
"maxLoad" : 68.62745098039215,
"averageThrottlePosB" : 29.11764705882353,
"minThrottlePosB" : 14.901960784313726,
"maxThrottlePosB" : 38.03921568627451,
"averageRpm" : 1216.25,
"minRpm" : 516.0,
"maxRpm" : 1486.0,
"averageThrottlePos" : 20.49019607843137,
"minThrottlePos" : 11.764705882352942,
"maxThrottlePos" : 36.86274509803921,
"averageIntakeAirTemp" : 85.5,
"minIntakeAirTemp" : 84.0,
"maxIntakeAirTemp" : 86.0,
"averageSpeed" : 13.517712865133625,
"minSpeed" : 0.0,
"maxSpeed" : 24.238657551274084,
"averageAltitude" : -1.575,
"minAltitude" : -1.9,
"maxAltitude" : -1.2,
"averageCommThrottleAc" : 25.392156862745097,
"minCommThrottleAc" : 6.2745098039215685,
"maxCommThrottleAc" : 38.431372549019606,
"averageEngineTime" : 32.25,
"minEngineTime" : 32.0,
"maxEngineTime" : 33.0,
"averageAbsLoad" : 40.3921568627451,
"minAbsLoad" : 18.431372549019606,
"maxAbsLoad" : 64.31372549019608,
"averageGear" : 0.0,
"minGear" : 0.0,
"maxGear" : 0.0,
"averageRelThrottlePos" : 19.019607843137255,
"minRelThrottlePos" : 4.705882352941177,
"maxRelThrottlePos" : 27.84313725490196,
"averageAccPedalPosE" : 14.607843137254902,
"minAccPedalPosE" : 9.411764705882353,
"maxAccPedalPosE" : 19.215686274509803,
"averageAccPedalPosD" : 30.19607843137255,
"minAccPedalPosD" : 18.823529411764707,
"maxAccPedalPosD" : 39.21568627450981,
"averageGpsSpeed" : 6.720000000000001,
"minGpsSpeed" : 0.0,
"maxGpsSpeed" : 12.82,
"averageShortTermFuelTrim2" : -0.5,
"minShortTermFuelTrim2" : -1.0,
"maxShortTermFuelTrim2" : 1.0,
"averageO211" : 9698.5,
"minO211" : 1191.0,
"maxO211" : 27000.0,
"averageO212" : 30349.0,
"minO212" : 28299.0,
"maxO212" : 32499.0,
"averageShortTermFuelTrim1" : -0.25,
"minShortTermFuelTrim1" : -2.0,
"maxShortTermFuelTrim1" : 4.0,
"averageMaf" : 2.4332170200000003,
"minMaf" : 0.77513736,
"maxMaf" : 7.0106280000000005,
"averageTimingAdvance" : 28.0,
"minTimingAdvance" : 16.5,
"maxTimingAdvance" : 41.0,
"averageClimb" : -0.025,
"minClimb" : -0.2,
"maxClimb" : 0.1,
"averageFuelPressure" : null,
"minFuelPressure" : null,
"maxFuelPressure" : null,
"averageTemp" : 199.0,
"minTemp" : 199.0,
"maxTemp" : 199.0,
"averageAmbientAirTemp" : 77.75,
"minAmbientAirTemp" : 77.0,
"maxAmbientAirTemp" : 78.0,
"averageManifoldPressure" : 415.4026475455047,
"minManifoldPressure" : 248.2073910645339,
"maxManifoldPressure" : 592.9398786541643,
"averageLongTermFuelTrim1" : 3.25,
"minLongTermFuelTrim1" : -1.0,
"maxLongTermFuelTrim1" : 7.0,
"averageLongTermFuelTrim2" : -23.5,
"minLongTermFuelTrim2" : -100.0,
"maxLongTermFuelTrim2" : 7.0,
"averageGPSAcceleration" : 1.0196509034930195,
"minGPSAcceleration" : 0.0,
"maxGPSAcceleration" : 1.9128551867763974,
"averageHeadingChange" : 0.006215710862578118,
"minHeadingChange" : 0.0,
"maxHeadingChange" : 0.013477895914941244,
"averageIncline" : null,
"minIncline" : null,
"maxIncline" : null,
"averageAcceleration" : 1.0196509034930195,
"minAcceleration" : 0.0,
"maxAcceleration" : 1.9128551867763974,
"count" : 4.0,
"eventTime" : ISODate("2017-07-18T18:11:30.000+0000"),
"eventId" : {
"year" : NumberInt(2017),
"month" : NumberInt(7),
"day" : NumberInt(18),
"hour" : NumberInt(18),
"minute" : NumberInt(11),
"quarter" : NumberInt(2)
},
"accountId" : "17350",
"vehicle" : "toyota-highlander-2005",
"driver" : "anupam",
"driverVehicle" : 12.0
}
That's quite a number of values for analysis! Which is a good sign for us - more values gives us more options to play with it.
As you may have realized by now, I have come to the final stage of building the model which is a traditional machine-learning task that is usually done in Python or R. So the final piece will be written in Python. You will find the entire code at 'driver_signature_build_model_scikit.py' in the 'machinelearning' directory.
Feature selection and elimination
As is common in any data-science project, one must first take a look at the data and determine if any features need to be eliminated. If some features do not make sense for the model we are building then those features need to be dropped. One quick observation is that fuel pressure and incline has nothing to do with driver signatures. So I will eliminate those values from any further consideration.
Specifically for this problem, you need do something special, which is a bit unusual, but required in this scenario.
If you look at the features carefully you will notice that some features are driver characteristics while others are vehicle characteristics. Thus it is important to not mix up the two sets. I have used my judgement to separate out the features into two sets as follows.
vehicle_features = [
"averageLoad",
"minLoad",
"maxLoad",
"averageRpm",
"minRpm",
"maxRpm",
"averageEngineTime",
"minEngineTime",
"maxEngineTime",
"averageAbsLoad",
"minAbsLoad",
"maxAbsLoad",
"averageAccPedalPosE",
"minAccPedalPosE",
"maxAccPedalPosE",
"averageAccPedalPosD",
"minAccPedalPosD",
"maxAccPedalPosD",
"averageShortTermFuelTrim2",
"minShortTermFuelTrim2",
"maxShortTermFuelTrim2",
"averageO211",
"minO211",
"maxO211",
"averageO212",
"minO212",
"maxO212",
"averageShortTermFuelTrim1",
"minShortTermFuelTrim1",
"maxShortTermFuelTrim1",
"averageMaf",
"minMaf",
"maxMaf",
"averageTimingAdvance",
"minTimingAdvance",
"maxTimingAdvance",
"averageTemp",
"minTemp",
"maxTemp",
"averageManifoldPressure",
"minManifoldPressure",
"maxManifoldPressure",
"averageLongTermFuelTrim1",
"minLongTermFuelTrim1",
"maxLongTermFuelTrim1",
"averageLongTermFuelTrim2",
"minLongTermFuelTrim2",
"maxLongTermFuelTrim2"
]
driver_features = [
"averageGPSLatitude",
"averageGPSLongitude",
"averageThrottlePosB",
"minThrottlePosB",
"maxThrottlePosB",
"averageThrottlePos",
"minThrottlePos",
"maxThrottlePos",
"averageIntakeAirTemp",
"minIntakeAirTemp",
"maxIntakeAirTemp",
"averageSpeed",
"minSpeed",
"maxSpeed",
"averageAltitude",
"minAltitude",
"maxAltitude",
"averageCommThrottleAc",
"minCommThrottleAc",
"maxCommThrottleAc",
"averageGear",
"minGear",
"maxGear",
"averageRelThrottlePos",
"minRelThrottlePos",
"maxRelThrottlePos",
"averageGpsSpeed",
"minGpsSpeed",
"maxGpsSpeed",
"averageClimb",
"minClimb",
"maxClimb",
"averageAmbientAirTemp",
"minAmbientAirTemp",
"maxAmbientAirTemp",
"averageGPSAcceleration",
"minGPSAcceleration",
"maxGPSAcceleration",
"averageHeadingChange",
"minHeadingChange",
"maxHeadingChange",
"averageAcceleration",
"minAcceleration",
"maxAcceleration"
]
vehicle_features = [
"averageLoad",
"minLoad",
"maxLoad",
"averageRpm",
"minRpm",
"maxRpm",
"averageEngineTime",
"minEngineTime",
"maxEngineTime",
"averageAbsLoad",
"minAbsLoad",
"maxAbsLoad",
"averageAccPedalPosE",
"minAccPedalPosE",
"maxAccPedalPosE",
"averageAccPedalPosD",
"minAccPedalPosD",
"maxAccPedalPosD",
"averageShortTermFuelTrim2",
"minShortTermFuelTrim2",
"maxShortTermFuelTrim2",
"averageO211",
"minO211",
"maxO211",
"averageO212",
"minO212",
"maxO212",
"averageShortTermFuelTrim1",
"minShortTermFuelTrim1",
"maxShortTermFuelTrim1",
"averageMaf",
"minMaf",
"maxMaf",
"averageTimingAdvance",
"minTimingAdvance",
"maxTimingAdvance",
"averageTemp",
"minTemp",
"maxTemp",
"averageManifoldPressure",
"minManifoldPressure",
"maxManifoldPressure",
"averageLongTermFuelTrim1",
"minLongTermFuelTrim1",
"maxLongTermFuelTrim1",
"averageLongTermFuelTrim2",
"minLongTermFuelTrim2",
"maxLongTermFuelTrim2"
]
driver_features = [
"averageGPSLatitude",
"averageGPSLongitude",
"averageThrottlePosB",
"minThrottlePosB",
"maxThrottlePosB",
"averageThrottlePos",
"minThrottlePos",
"maxThrottlePos",
"averageIntakeAirTemp",
"minIntakeAirTemp",
"maxIntakeAirTemp",
"averageSpeed",
"minSpeed",
"maxSpeed",
"averageAltitude",
"minAltitude",
"maxAltitude",
"averageCommThrottleAc",
"minCommThrottleAc",
"maxCommThrottleAc",
"averageGear",
"minGear",
"maxGear",
"averageRelThrottlePos",
"minRelThrottlePos",
"maxRelThrottlePos",
"averageGpsSpeed",
"minGpsSpeed",
"maxGpsSpeed",
"averageClimb",
"minClimb",
"maxClimb",
"averageAmbientAirTemp",
"minAmbientAirTemp",
"maxAmbientAirTemp",
"averageGPSAcceleration",
"minGPSAcceleration",
"maxGPSAcceleration",
"averageHeadingChange",
"minHeadingChange",
"maxHeadingChange",
"averageAcceleration",
"minAcceleration",
"maxAcceleration"
]
Having done this, now we need to build two different models - one to predict the driver and another one to predict the vehicle. It will be an interesting exercise to see which of these two models have better accuracy.
Reading directly from database instead of CSV
For completeness sake let me first give you two utility functions that are used to pull data out of the MongoDB database.
def _connect_mongo(host, port, username, password, db):
""" A utility for making a connection to MongoDB """
if username and password:
mongo_uri = 'mongodb://%s:%s@%s:%s/%s' % (username, password, host, port, db)
conn = MongoClient(mongo_uri)
else:
conn = MongoClient(host, port)
return conn[db]
def read_mongo(db, collection, query={}, projection='', limit=1000, host='localhost', port=27017, username=None, password=None, no_id=False):
""" Read from Mongo and Store into DataFrame """
db = _connect_mongo(host=host, port=port, username=username, password=password, db=db)
cursor = db[collection].find(query, projection).limit(limit)
datalist = list(cursor)
sanitized = json.loads(json_util.dumps(datalist))
normalized = json_normalize(sanitized)
df = pd.DataFrame(normalized)
return df
def _connect_mongo(host, port, username, password, db):
""" A utility for making a connection to MongoDB """
if username and password:
mongo_uri = 'mongodb://%s:%s@%s:%s/%s' % (username, password, host, port, db)
conn = MongoClient(mongo_uri)
else:
conn = MongoClient(host, port)
return conn[db]
def read_mongo(db, collection, query={}, projection='', limit=1000, host='localhost', port=27017, username=None, password=None, no_id=False):
""" Read from Mongo and Store into DataFrame """
db = _connect_mongo(host=host, port=port, username=username, password=password, db=db)
cursor = db[collection].find(query, projection).limit(limit)
datalist = list(cursor)
sanitized = json.loads(json_util.dumps(datalist))
normalized = json_normalize(sanitized)
df = pd.DataFrame(normalized)
return df
The function above is Pandas-friendly - it reads data from the MongoDB database and returns a Pandas data-frame so that you can get to work immediately with your machine-learning part.
In case you are not comfortable with MongoDB, I am giving you the entire dataset of the aggregated values in CSV format so that you can import it in any database you wish. The file is in GZIP format - so you need to unzip it before reading it. For those of you who are comfortable with MongoDB, here is the entire database dump.
Building a Machine Learning model
Now it is time to build the learning model. At program invocation two parameters are needed - the database host and which feature set to build the model for. This is handled in the code as follows:
DATABASE_HOST = argv[0]
CHOSEN_FEATURE_SET = argv[1]
readFromDatabase = True
read_and_proceed = False
DATABASE_HOST = argv[0]
CHOSEN_FEATURE_SET = argv[1]
readFromDatabase = True
read_and_proceed = False
Then I have some logic for setting the appropriate feature set within the application.
if (CHOSEN_FEATURE_SET == 'vehicle'):
features = vehicle_features
feature_name = 'vehicle'
class_variables = ['vehicle'] # Declare the vehicle as a class variable
elif (CHOSEN_FEATURE_SET == 'driver'):
features = driver_features
feature_name = 'driver'
class_variables = ['driver'] # Declare the driver as a class variable
else:
features = all_features
feature_name = 'driverVehicleId'
class_variables = ['driverVehicleId'] # Declare the driver-vehicle combo as a class variable
if readFromDatabase:
if CHOSEN_FEATURE_SET == 'driver': # Choose the records only for one vehicle which has multiple drivers
df = read_mongo('obd2', 'vehicle_signature_records', {"vehicle": {"\)regex" : ".*gmc-denali.*"}, "eventTime": {"\(gte": startTime, "\)lte": endTime} }, {"_id": 0}, 1000000, DATABASE_HOST, 27017, None, None, True )
else:
df = read_mongo('obd2', 'vehicle_signature_records', {"eventTime": {"\(gte": startTime, "\)lte": endTime} }, {"_id": 0}, 1000000, DATABASE_HOST, 27017, None, None, True )
if (CHOSEN_FEATURE_SET == 'vehicle'):
features = vehicle_features
feature_name = 'vehicle'
class_variables = ['vehicle'] # Declare the vehicle as a class variable
elif (CHOSEN_FEATURE_SET == 'driver'):
features = driver_features
feature_name = 'driver'
class_variables = ['driver'] # Declare the driver as a class variable
else:
features = all_features
feature_name = 'driverVehicleId'
class_variables = ['driverVehicleId'] # Declare the driver-vehicle combo as a class variable
if readFromDatabase:
if CHOSEN_FEATURE_SET == 'driver': # Choose the records only for one vehicle which has multiple drivers
df = read_mongo('obd2', 'vehicle_signature_records', {"vehicle": {"\)regex" : ".*gmc-denali.*"}, "eventTime": {"\(gte": startTime, "\)lte": endTime} }, {"_id": 0}, 1000000, DATABASE_HOST, 27017, None, None, True )
else:
df = read_mongo('obd2', 'vehicle_signature_records', {"eventTime": {"\(gte": startTime, "\)lte": endTime} }, {"_id": 0}, 1000000, DATABASE_HOST, 27017, None, None, True )
The following part is mostly boiler-plate code to break up the dataset into a training set, test set and validation set. While doing so all null values are set to zero as well.
# First randomize the entire dataset
df = df.sample(frac=1).reset_index(drop=True)
# Then choose only a small subset of the data, frac=1 means choose everything
df = df.sample(frac=1, replace=True)
df.fillna(value=0, inplace=True)
train_df, test_df, validate_df = np.split(df, [int(.8*len(df)), int(.9*len(df))])
df[feature_name] = df[feature_name].astype('category')
y_train = train_df[class_variables]
X_train = train_df.reindex(columns=features)
X_train.replace('NODATA', 0, regex=False, inplace=True)
X_train.fillna(value=0, inplace=True)
y_test = test_df[class_variables]
X_test = test_df.reindex(columns=features)
X_test.replace('NODATA', 0, regex=False, inplace=True)
X_test.fillna(value=0, inplace=True)
y_validate = validate_df[class_variables]
X_validate = validate_df.reindex(columns=features)
X_test.replace('NODATA', 0, regex=False, inplace=True)
X_validate.fillna(value=0, inplace=True)
# First randomize the entire dataset
df = df.sample(frac=1).reset_index(drop=True)
# Then choose only a small subset of the data, frac=1 means choose everything
df = df.sample(frac=1, replace=True)
df.fillna(value=0, inplace=True)
train_df, test_df, validate_df = np.split(df, [int(.8*len(df)), int(.9*len(df))])
df[feature_name] = df[feature_name].astype('category')
y_train = train_df[class_variables]
X_train = train_df.reindex(columns=features)
X_train.replace('NODATA', 0, regex=False, inplace=True)
X_train.fillna(value=0, inplace=True)
y_test = test_df[class_variables]
X_test = test_df.reindex(columns=features)
X_test.replace('NODATA', 0, regex=False, inplace=True)
X_test.fillna(value=0, inplace=True)
y_validate = validate_df[class_variables]
X_validate = validate_df.reindex(columns=features)
X_test.replace('NODATA', 0, regex=False, inplace=True)
X_validate.fillna(value=0, inplace=True)
Building a Random Forest Classifier and saving it
After trying out various different classifiers, with this dataset, it turns out that a Random Forest classifier gives the best accuracy. Here is the graph showing accuracy of the different classifiers used with this data set. The two best algorithms turn out to be Classification & Regression and Random Forest Classifier. I chose the Random Forest Classifier since this is an ensamble techique and will have better resilience.

This is what you need to do to build a Random Forest classifier with this dataset.
dt = RandomForestClassifier(n_estimators=20, min_samples_leaf=1, max_depth=20, min_samples_split=2, random_state=0)
dt.fit(X_train, y_train.values.ravel())
joblib.dump(dt, model_file)
print('...done. Your Random Forest classifier has been saved in file: ' + model_file)
dt = RandomForestClassifier(n_estimators=20, min_samples_leaf=1, max_depth=20, min_samples_split=2, random_state=0)
dt.fit(X_train, y_train.values.ravel())
joblib.dump(dt, model_file)
print('...done. Your Random Forest classifier has been saved in file: ' + model_file)
After building the model, I am saving it in a file (line 4) so that it can be read easily when doing the prediction. To find out how well the model is doing, we have to use the test set to make a prediction and evaluate the model score.
y_pred = dt.predict(X_test)
y_test_as_matrix = y_test.as_matrix()
print('Completed generating predicted set')
print ('Confusion Matrix')
print(confusion_matrix(y_test, y_pred))
crossValScore = cross_val_score(dt, X_validate, y_validate)
model_score = dt.score(X_test, y_test_as_matrix)
print('Cross validation score = ' + crossValScore)
print('Model score = ' + model_score)
print ('Precision, Recall and FScore')
precision, recall, fscore, _ = prf(y_test, y_pred, pos_label=1, average='micro')
print('Precision: ' + str(precision))
print('Recall:' + str(recall))
print('FScore:' + str(fscore))
y_pred = dt.predict(X_test)
y_test_as_matrix = y_test.as_matrix()
print('Completed generating predicted set')
print ('Confusion Matrix')
print(confusion_matrix(y_test, y_pred))
crossValScore = cross_val_score(dt, X_validate, y_validate)
model_score = dt.score(X_test, y_test_as_matrix)
print('Cross validation score = ' + crossValScore)
print('Model score = ' + model_score)
print ('Precision, Recall and FScore')
precision, recall, fscore, _ = prf(y_test, y_pred, pos_label=1, average='micro')
print('Precision: ' + str(precision))
print('Recall:' + str(recall))
print('FScore:' + str(fscore))
Many kinds of evalution metrics are calculated and printed in the above code segment. The most important one that I tend to look at is the overall model score, but the others will give you a good idea of the bias and variance which indicates how resilient your model is with respect to changing values.
Measure of importance
One interesting analysis is to figure out which of the features is the most impactful on the result. This can be done using the simple code fragment below:
importance_indices = {}
for z in range(0, len(dt.feature_importances_)):
importance_indices[z] = dt.feature_importances_[z]
sorted_importance_indices = sorted(importance_indices.items(), key=operator.itemgetter(1), reverse=True)
for k1 in sorted_importance_indices:
print(features[int(k1[0])] + ' -> ' + str(k1[1]))
importance_indices = {}
for z in range(0, len(dt.feature_importances_)):
importance_indices[z] = dt.feature_importances_[z]
sorted_importance_indices = sorted(importance_indices.items(), key=operator.itemgetter(1), reverse=True)
for k1 in sorted_importance_indices:
print(features[int(k1[0])] + ' -> ' + str(k1[1]))
Prediction results and Conclusion
After running the two cases, namely driver prediction and vehicle prediciton, I am typically getting the following scores.
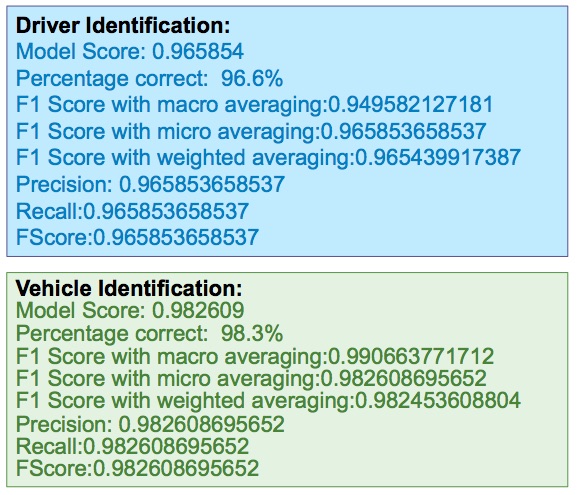
This is encouraging given that there was always an apprehension about the score not being accurate enough due to the low frequency of data collection. This is an important factor, since we are creating this model out of the instantaneous time derivatives of values, and a low sampling rate will introduce a significant error. The dataset has 13 different driver vehicle combinations. There isn't a whole lot of driving data other than the experiments that were done, but with an accuracy that is 95% or above, there may be some value in this approach.
Another interesting fact is that the vehicle prediction is coming out to be more accurate than the driver. In other words, the parameters being emitted by the car tend to characterize the car more heavily than the driver. Most drivers drive the same way, but the machine characteristics of the car tend to distinguish them more clearly.
Commercial Use Cases
I have showed you an example of many such applications that can be done with an approach like this. It just involves equipping your car with a smart device like a Raspberry Pi and the rest is all backend server-side work. Here are all the use-cases that I can think of. You can take up any of these as your own project and attempt to find a solution.
- Parking assistance
- Adaptive collision detection
- Video evidence recording
- Detect abusive driving
- Crash detection
- Theft detection
- Parking meter
- Mobile hot-spot
- Voice recognition
- Connect racing equipment
- Head Unit display
- Traffic sign warning
- Pattern of usage
- Reset fault codes
- Driver recognition (this is already demonstrated here!)
- Emergency braking alert
- Animal overheating protection
- Remote start
- Remote seatbelt notifications
- Radio volume regulation
- Auto radio off when window down
- Eco-driving optimization alerts
- Auto lock/unlock
Commercial product
After doing this experiment building a Raspberry Pi kit from scratch, I found out that there is a product called AutoPi that you can buy which will cut short a lot of the hardware setup. I have no affiliation with AutoPi, but I thought it is interesting that this subject is being treated quite seriously by some companies in Europe.











