Data Science
Blog articles pertaining to Data Science, Machine Learning, Hardware, Software and Personal musings

Anupam Bagchi
Anupam Bagchi has been in the Information Technology industry since the early nineties in the Silicon Valley. He has a Ph.D in Robotics and is deeply interested in recent advances in Machine Learning and Artificial Intelligence. Professionally, he is a Data Scientist. His primary hobby is photography.
Knowns and Unknowns - A creative approach to problem solving

 Back when the US was having a war with Iraq, Donald Rumsfield would come on TV and give a status of the war. In one of those updates, he mentioned the status in terms of "known" elements and "unknown" elements. He introduced a concept that it very useful in the business world. Here is my interpretation of the same concept applied to life in general. This holds true for business exploration, assessing project risk, research and development, or engineering design - whereever you are attempting to find a solution to a new problem.
Back when the US was having a war with Iraq, Donald Rumsfield would come on TV and give a status of the war. In one of those updates, he mentioned the status in terms of "known" elements and "unknown" elements. He introduced a concept that it very useful in the business world. Here is my interpretation of the same concept applied to life in general. This holds true for business exploration, assessing project risk, research and development, or engineering design - whereever you are attempting to find a solution to a new problem.
The Known-Unknown Matrix
Assuming you are attempting to find the solution to a complex problem, you will encounter may items which will fall in any of these four categories.
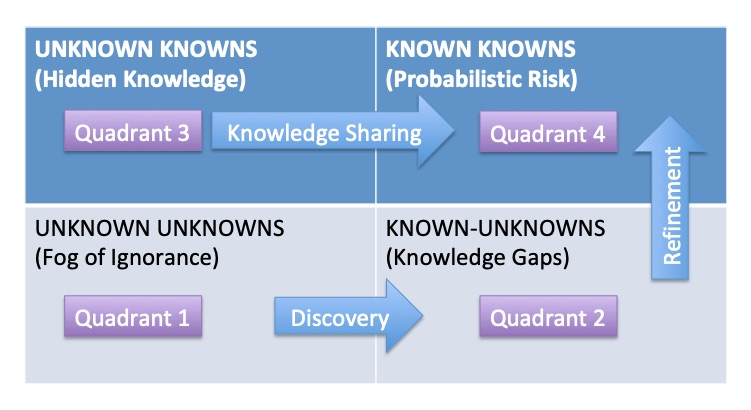
The goal of every project is to move all items towards the KNOWN KNOWNS category (Quadrant 4). However as you start off and move along - analysing every element in the project one-by-one, many things start off in the other quadrants (1, 2 or 3) and then slowly move to the adjacent quadrants till it reaches the Known-knowns quadrant. Let us analyze the items in each of these four quadrants one by one.
KNOWN KNOWNS (Quadrant 4)
At the project inception, these are the elements you generally work with. Breaking down a project into several sub-projects, the goal of each sub-project is clearly defined, as is the path to reach it. So your work will involve accomplishing the task with all known elements in sight, using a methodology that is also known to you. However there are always risks in any project that are beyond control. In this case, those risks are also known to you, and the steps to counter those risks, when they do arrive, are also known to you. In other words you are well prepared to complete the project given the probability of the defined risks that are already known to you. Thus this quadrant is about the Probabilistic Risks of a project.
A world where everything is known is awesome - including the project goals, the approach to achieve those goals as well as the risk elements of the project, and the means to counteract them. But alas, the world is not so simple. And honestly if it was that simple, there would be no challenge in undertaking a new project, because you are treading on a beaten path all the time with predictable results. This brings us to the other known quadrant.
KNOWN UNKNOWS (Quadrant 2)
Since you are not the only person who has
References:
Managing effectiveness of Email campaigns

A Behavior Analysis Problem
Despite the growth of alternate communication means like Chat applications (Whatsapp, Slack, Snapchat), Social web-sites (Facebook, Google Plus, Twitter), communicating via icons (Emojis) and images (Instagram), the good old Email is not yet dead. Almost all companies still rely on Email to not only run their business, but also to do marketing to their customers. This, in itself, has evolved into a field of study. The main concern facing any marketing manager is to control the amount of email to send to their clients so that the customer stays interested in the company and does not unsubscribe because of too much junk mail. So the balance between too much mail and too little mail is very sensitive.
We can employ data science to solve this problem. The problem solved here is taken from a real company's data and was presented to me as a test. So I thought this is good problem to solve and demonstrate the use of data science. Emailing customers too frequently can cause them to unsubscribe from the email list. Sending them too many mails will lead them to not open emails that can cause promotional emails to be sent to their junk mailbox. The goal is to find out the optimum amount of emails to be sent to each customer so that they stay interested over time. Note that this number is different for every customer. We want to predict a customer's propensity to open an email in the future based on observed historical trends as well as their propensity to unsubscribe if they do open the email.
The Dataset
Before I start describing the dataset, you may be inclined to see it first. To introduce some variety in my solution approach - and since most of the data is tabular in fashion, I have decided to use a relational database (MySQL) to store the data, and query it, using JOINs if necessary to generate my feature set. You can download the entire dump of the MySQL database and restore it on your local machine to get started.
What data do we have?
We have data in 5 tables as follows:
- Campaign Types - A historical list of campaigns with date and campaign type
- User Info - a list of user ids along with registration date and the source from where their email was acquired
- Sends - a list of dates when an email was sent to the user and a flag indicating if the email was opened
- Opens - a list of dates when an email was opened by the subscriber and unsubscribed
- Events - a list of events pertaining to each user along with counts. The count represents different things depending on the type of event.
Let me describe in detail what each column in the given tables mean.
Campaign Type
| Column | Data Type | Description |
| launch_id | Date | Unique identifier of a campaign by date of send. |
| camptype | String | Type of campaign (email send), where “Heavy Promo”, “Light Promo”, “Evergreen” (No Promo) refer to the magnitude of promo offer, and “Primary Messaging”/”Secondary Messaging” refer to the degree to which the promotion is messaged within the email content. |
User Info
| Column | Data Type | Description |
| riid | Integer | Unique identifier of a customer |
| aq_dt | Datetime | Date customer's email was acquired as stored in current email system |
| sub_source | String | Desciption of where the customer registered their email |
Sends
| Column | Data Type | Description |
| riid | Integer | Unique identifier of a customer |
| campaign_send_dt | Datetime | Send date of campaign |
| opened | Integer | 0 or 1, indicator of whether or not a given riid opened a given campaign |
Opens
| Column | Data Type | Description |
| riid | Integer | Unique identifier of a customer |
| campaign_send_dt | Datetime | Send date of campaign |
| optout | Integer | 0 or 1, indicator of whether or not a given riid opened a given campaign and unsubscribed |
Events
| Column | Data Type | Description |
| riid | Integer | Unique identifier of a customer |
| event | String | Name of the event the record is associated:
|
| event_captured_dt | Datetime | Date an event was recorded. |
| cnts | Integer | Different aggregate measures depending on the associated event:
|
Understanding the dataset
Before we jump into a predictive model building, let us analyze the data to understand it better.
Aggregate open rate
As a first exercise, let us attempt to detemine the aggregate open rate. In other words, what percentage of people actually opened their email. This is a very simple ratio determined from the count of emails opened vs. count of email. We can do this in one SQL statement as follows:
The answer is about 18%.
Aggregate unsubscribe per open rate
Of the people who opened their email, how many got irritated and unsubscribed? Again, this is a simple SQL query on the "opens" table as follows:
The answer is about 1.4%.
Aggregate open rate ordered by launch Id
How about calculating the open rate based on launch Id. Since one mail is sent every day, we can group the results by launch date and expect the same result. This is a simple group by query as follows:
The answer lies between 11% and 42% that happened only once when mails sent were too low.
Aggregate open rate based on registration source
We could also group the results based on other criteria, like sub_source. This query will be a bit longer, but here it is as given below. Note that we are using the WITH statement available in MySQL that is a more recent addition to the MySQL syntax.
A ratio is expected to average 18% or so, and the results look plausible.
Aggregate open rate based on month of acquisition
Another similar criteria to group the results is month of acquisition. Here is the query for that.
The user data appears to have some problems (NULL values) for earlier dates. This was confirmed as those were reported to have been migrated from a legacy email system, and were not completely correct.
To open or not
So far we had no need to use data-science tools as most of the analysis was simple enough to handle through SQL. Let's try to do a slightly more involved analysis. Before a data scientist attempts to do some prediction, he/she has to work with some conjectures or hypotheses. These are theories based on intuition and one must be able to either prove or disprove it using derivation from the data.
One of the assumptions is that a customer's propensity to open an email as well as their propensity to unsubscribe (after opening the mail) may be related to their tenure. To analyze this theory we need a dataset that has the tenure (difference between the mail's send date and the acquisition date) alongside for each record in the "send" table.
How do we get the tenure in the "sends" table? This is done through a simple JOIN statement as follows:
The statement above prints only 10 rows, but the tenure has been elegantly inserted as an extra column in this table. If our theory is correct, there should be a positive relationship between the "opened" state and tenure. Since the "opened" state is a discrete variable which takes only two values (0 and 1), we may be able to show a corelation if we plot a histogram of opened state against tenure range.
Since I have made my hands dirty with SQL, let me become a bit bold and try to write a SQL query to plot a side-ways histogram using just SQL. Yes, you were expecting me to write a Python program or an R program to draw a beautiful histogram, but I am feeling a bit lazy now, and if SQL can give me a decent graphic, why not?
This SQL query needs some explanation. In the internal SQL query "select sends.riid, sends.campaign_send_dt, sends.opened, user_info.aq_dt, user_info.sub_source,
DATEDIFF(sends.campaign_send_dt, user_info.aq_dt) AS tenure from sends left join user_info
ON sends.riid = user_info.riid where opened = 1" we are just creating a joined table with only the entries that were opened. Then the rest of query is creating buckets with a range of 100 in each bucket. The variable "COUNT" is the count of entries in each bucket and the "bar" is a poor man's histogram.
We see that if the tenure is low, then the person is more likely to open the email. Those with a higher tenure tend not to open their email. This may be explained by the fact that interest in the email dwindles with time - which I believe is natural to expect.
To unsubscribe or not
A related problem to the above is to figure out how tenure affects someone's likelyhood of unsubscribing. For that we can use the "opens" table and do a similar query on the "optout" column. This will tell us if people who have a long tenure are more likely to unsubscribe or not. To continue the tradition, I am going to write this query in SQL again.
It is very clear from the histogram above that people with less tenure tend to opt out of email campaigns quickly. Those whose have been a subscriber for a long time will hesitate to opt out of email campaigns. The highest rate of opt-outs come between the first 200 days or so.
Predicting a customer's reaction
I am finally going to solve a real data-science problem with this data-set. For those of you who believe that I have been dilly-dallying with SQL all this while, this would be interesting.
We would like to predict the likelihood that a customer will open an email sent on a given day in the future for a given campaign type. Is it also possible to predict if the person who opens the email will unsubscribe? Let us try first create the dataset and then fit a model on that dataset.
To solve this problem, I would like to create a dataset that has the following columns.
- User id (riid)
- Date (just for reference, not to be used in dataset)
- Tenure on that day
- Type of campaign (camptype)
- Source of user's email address (sub_source)
- Number of times the user opened the email that day
- Whether the user unsubscribed from list that day
- Sum total of items purchased by an individual on a given day
Most of the information is in table "events", but it needs to be augmented with additional information from other tables. To do so we have to do a few more joins. Ideally I would like to do everything in one join statement as follows:
But alas, the datasize is too big to do this in one shot. We have about 8.3 million records in the events table! So we have to break up this query into several parts and do some indexing in between to make it work faster. Here is the trick.
We would like to do the joins in three stages - joining one table at a time and saving the result to a different table. (This is similar to the MapReduce paradigm where each MapReduce step writes its result to the disk before the next stage begins). Here are the steps to do it for this problem. We are creating three tables called dataset1, dataset2 and dataset3 - each of them them bigger than the previous one and pulling in some columns from different tables. Our final table will be dataset3 which will be used for the machine learning exercise.
Here is how you will create the first dataset.
Notice that we have the same number of rows in table dataset1 as the events table. The next stage includes more data from the campaign_types table
Before we do the final join, it is necessary to make the database efficient as this join is quite exhaustive. So let's create some indices to make the database queries efficient. I am going to create four indices as follows:
The final join brings in data from the opens table into this composite table.
It turns out that the data came out in a slightly different format than what I had expected, but it is workable. Here is a small sample of the resulting table which will be our starting dataset for the rest of the machine learning exercise.
I am going to take one more step with processing the data to make my life simpler for the following step. I am about to use a standard machine learning package to process my data, and so I am going to export the entire dataset to a file format that is friendly to most packages. Yes, it is possible to read the data from the database directly (and I will show it in a different article some day), but at the moment I want to solve this problem with the tools already availble in the machine learning package without writing anything complicated.
Therefore I am going to export the entire table into CSV format so that I can read it from a file. The export is done simply through the following statement:
Note that I am only including the records where the camptype and optout variables have either a 0 or a 1 (not NULL). The resulting file looks like this:
You can download the CSV file to look at it in its entirety.
Predicting likelihood that the user will open the email
With the dataset thus created, we are now ready to fit a machine learning model over it. We used to have 8.3 million records in this dataset, but after eliminating all those records that have either a NULL camptype or a NULL optout field, the resuting records amount to only 186,584 records. Our job is to make a prediction based on that. I would like to be able to fit a machine learning model using the entire dataset. For that I am going to use SPARK as my tool-set. Since the output is binary (i.e. 0 for open and 1 for optout) I am going to use LogisticRegression to fit a model.
You will find the entire code written in Java in GitHub. Clone this repository to follow along.
Prerequisites for running this program are Apache SPARK that you need to download and install on your computer first. I will be using Spark in standalone mode, so there should be no difficulty to run it. Make sure that 'spark-submit' is in your $PATH variable.
I have created the repository in such a way that the dataset is in the folder 'data' under root. After cloning the repository look at the Java file CustomerOpenResponsePredictor.java. Let us look at the main() function of this class to see the logic behind it.
First task is the create the Spark session which happens in line 1. In lines 7-10 I am loading the data from the CSV session. (Note that since this is multi-threaded, the data will be read in parallel in chunks through different threads). This dataset has three fields that are given as strings, but they can be converted to categorical variables (i.e. they are basically enumerations of state). Spark offers a way to do this through the StringIndexer class. Lines 12 - 14 define three different indexers that convert the columns event, sub_source and camptype to eventIndex, sub_sourceIndex and camptypeIndex respectively. The remaining variables are all integers, so LogisticRegression will work fine in this case. Lines 16-18 do the actual conversion of these three columns to integers from String. The next step is to split the data randomly into two sets - one for training and another for validation. I am using the randomSplit() function to do that in lines 22 to 25. After doing this, I now have two datasets with a 80%-20% split.
Feature Set and Output Value
To be clear, here are all the parameters in the feature set (the input X vector):
- eventIndex - the enumerated version of the type of event
- cnts - the count of clicks on that event type
- sub_sourceIndex - the enumerated version of the source of email
- tenure - the amount of time the user has been a subscriber
- camptypeIndex - the enumerated version of the type of campaign
The output (y) is a binary value "optout" which represents whether the user will stay (represented by 0) or unsubscribe (represented by 1).
Note that all the columns present in the dataset are not to be fed into the LogisticRegression model builder. Only certain meaningful columns must be selected for the model building. I am going to use the VectorAssembler class to create my feature set. Lines 1 - 3 creates a composite output column called "features" that comprises of the columns eventIndex, cnts, sub_sourceIndex, tenure and camptypeIndex. These are our input variables. The LogisticRegression model is built in line 6 with epochs as 10, regularization parameter as 0.3 and elastic network parameter as 0.8. The input feature set is the "features" column I just created and the output is the "optout" column. Lines 13 to 15 are the Spark steps to create a workflow pipeline. Line 15 creates the actual learning model from the dataset. Line 17 uses the test dataset to make a prediction based on this model. Lines 21 to 26 finds out the accuracy of the model using a simple comparison of the predicted value and the original value of optout.
One point to note about software versions: I am using Spark 2.3.1 and JDK 1.8 to do my work. This combination worked for me. (JDK 10 has some compatibility problems with Spark 2.3, so avoid this combination.)
To compile type the following:
To run the program type:
Your output is going to look somewhat like this:
Since the model does the splitting between the training and test dataset randomly, the results will be different each time. For most of my runs, the accuracy of the model varies between 98.2 to 98.5 percent. This is pretty good given that we had to crunch so much data to come to this conclusion.
How to use this information?
Now the big question is, what can we do about it? Since we are able to predict quite accurately whether the user will unsubscribe, it is best not to send the email to that user. The next step in deployment of this model is to keep it running as a web-service, and before sending an email, check (through the web-service) if the user is likely to opt out of the emails. If so, it is best to suppress sending that email to the user. Awesome! So now we have found an innovative way to retain customers.
Conclusion
I am not going to disappoint any person who came to this page thinking that they will get nuggets of information and instead found a bunch of SQL and mathematics. Here are some tips for really sending email for your campaigns. I am reproducing below for your reference.
-
Try sending email on weekends: Based on data of over 9 billion emails (yes, billion with a “b”) provided by Mailchimp, Saturdays and Sundays have notably higher Click Thru Rates (CTRs); this is coupled with said data showing unsubscribes peak on Tuesdays. These rates include both B2B and B2C emails (although given the volume, are presumably skewed towards B2C.)
-
Send very early in the morning: Data layered over Hubspot survey results reveal while recipients report reading email throughout the day, CTRs peak between 6 – 7 am (localized). And while unsubscribes also peak in the morning, they also spiked late in the evening (when readership dropped off).
-
Optimize your email for mobile: a bit of a no-brainer; surveys cited 80% of the respondents read email on mobile devices, highlighting the importance of making sure your email doesn’t look like scrambled eggs on mobile.
-
Include reference data in your email: Make email searchable. Focus group participants report using email inboxes as an archive of ‘elite’, personal data, referring back to it on an informational basis.
-
Use lots of links in your email: While this may be counterintuitive, Zarrella says there is strong correlation between a greater number of links and higher CTRs. Data also shows lower unsubscribes as the number of links increase. (This may be, of course, because the unsubscribe link is tougher to find…)
-
Serialize and label your email: Using continuity and content-based words such as “[this] week’s,” “newsletter,” or “digest” in the subject line leads to the higher CTRs. Conversely, the traditional “spam” words continue to hold true. [Bonus hint: monitor your spam box for common “trigger” words to avoid.]
-
Give your subscribers special access: Focus groups find people like getting offers specific to them, offers with exclusivity built into them. Another no-brainer, but worth repeating.
-
Send email from people they’ve heard of: Be it a celebrity name or a guru, people like receiving emails from names they recognize.
-
Do not be afraid to send too much email: Unsubscribes are notably higher for organizations that send one or two emails per month; as the frequency of emails reaches eight the number declines.
-
Your newest subscribers are your best: While most subscribers opt out shortly after first subscribing to an email, CTRs early on are also at a high – proving the adage “get ‘em while they’re hot.”
-
Ask people to follow you, not forward emails: It’s not just using social media, but using it wisely. Survey data showed about 80% people either never or rarely forward or Tweet commercial email, even with the advent of ‘share’ and ‘tweet’ buttons. Instead, get people to follow you through Facebook, Twitter, etc. driving prospects to subscribe to your email.
-
Make them want to get your emails: 70% of people report reading most or all of their email, and 58% have separate “junk” inboxes. Given that, Zarella stressed incorporating all the best practice takeaways detailed to ensure your message gets to people’s “good” email address, read, and acted upon.
So that's it folks. You are now an Email marketing ninja. Go out and start practicing some of these ideas.
Driver Signatures from Car Diagnostic Data captured using a Raspberry Pi: Part 3 (Building a data model and predicting driver)

In the first and second part of this series I described how to set up the hardware to read data from the OBD port using a Raspberry Pi and then upload it to the cloud. You should read the first part and second part of this series before you read this article.
Having done all the work to capture and transport all the data to the cloud, let us figure out what can be done on the cloud to introduce Machine Learning. To understand the concepts given in this article you will need to be familiar with Javascript and Python. Also, I am using MongoDB as my database - so you will need to know the basics of a document-oriented database to follow the example code here. MongoDB is not only my storage engine here, but also my compute engine. By that, I mean that I am using the database's scripting language (Javascript) to pre-process data that will ultimately be used for machine learning. The Javascript code given herein executes (in a distributed manner) inside the MongoDB database. (Some people get confused when they see Javascript, assuming that it requires a server like NodeJS to run - not here.)
Introduction to the Solution
To set the introduction, I will describe the following three tasks in this article:

- Read the raw records and augment it with additional derived information to generate some extra features used for machine learning that is not directly sent by the Raspberry Pi. Derivatives based on time interval between readings can be used to derive instanteous velocity, angular velocity and incline. These are inserted into the derived records when we save it to another MongoDB collection (also known as 'table' in relational database parlance) to be used later for generating the feature sets. I will be calling this collection 'mldataset' in my database.
- Read the 'mldataset' and extract features from the records. The feature set is saved into another collection called 'vehicle_signature_records'. This is an involved process since there are so many fields found in the raw records. In my case, the feature sets are basically three statistical averages (minimum, average and maximum) of all values aggregated over a 15 second period. The other research papers on this subject take the same approach, but the time interval over which the aggregates are taken vary based on the frequency of the readings. The recommended frequency is 5 Hz i.e. 1 record-set per 0.2 second. But as I mentioned in article 2 of this series, we are unable to read data that fast on a serial connection over ELM 327. The maximum speed that I have been able to observe (mostly in modern cars) is 1 record-set in 0.7 seconds. Thus a 15 second aggregation makes more sense in our scenario. Due to this, the accuracy of the prediction may be affected - but we will accept that as a constraint. The solution methodology remains the same though.
- Apply a learning algorithm on the feature-set to learn the driver behavior. Then the model needs to be deployed on a machine in the cloud. In real-time we need to calculate the same aggregates over the same time interval (15 seconds) and feed it into the model to come up with a prediction. To confirm the driver we will need to take readings over several intervals (5 minutes will give 20 predictions) and then use the value with the maximum count (i.e. modal value).
Augmenting raw data with derivatives
This is a very common scenario in IoT applications. When generated data comes from a human being, it always has useful information at the surface. All you need to do is scan the logs and extract it. An example of this is finding the interests of the user based on user-clicks in a shopping cart scenario - all the items that the user has seen on the web-site are directly found in the logs. However an IoT device is dumb, has no emotion, has no special interests. All data coming from an IoT device is the same consistent boring stream. So where do you dig to find useful information? The answer to this question is in the time-derivatives. The variation in values from one reading and the other provides useful insight into the behavior. Examples of these are velocity (derivative of displacement found from GPS readings), acceleration (derivative of velocity) and jerk (derivative of acceleration). So you see, augmenting raw data to put this extra information is extremely useful for IoT applications.
In this step I am going to write some Javascript code (that runs inside the MongoDB database) to augment raw data with derivatives for each record. You will find all this code in the file 'extract_driver_features_from_car_readings.js' which is located inside the 'machinelearning' folder. If you are wondering where to find the code, it is in Github at this location https://github.com/anupambagchi/driver-signature-raspberry-pi.
Processing raw records
Before diving into the code, let me clarify a few things. The code is written to run as a cronjob on a machine on the same network as the MongoDB database - so that it is accessible. Since it runs as a cron task, we need to know how many records to process from the raw data table. Thus we need to do some book-keeping on the database. We have a special collection called 'book_keeping' for this purpose where we store some book-keeping information. One of them is the last date till when we have processed the records. The data (in JSON format) may look like this:
To determine where we need to pick up the record processing from, here is one way to do this in a MongoDB script written in Javascript.
The 'else' part of the logic above is for the initialization phase when we run it for the first time - we just want to pick up all records for the past year.
Keeping track of driver vehicle combination
Another book-keeping task is to keep track of the driver-vehicle combinations. To make the job easier for the machine learning algorithm, this should be converted to indices. Those indices are maintained in the database in another book-keeping collection called 'driver_vehicles'. This collection looks somewhat like this:
These are the names of vehicles with their drivers. Each combination has been assigned a number against it. When a driver-vehicle combination is encountered, the program looks to see if that combination already exists or not. If not, then it adds a new combination. Here is the code to do it.
You can see that a 'find' call to the MongoDb database is being made to read the hash-table in memory.
The next task is to query the raw collection to find out which records are new since the last time it ran.
NOTE: In the code segments below the dollar symbol will show up as '@'. Please make the appropriate substitutions when you read it. The correct code may be found in the github repository.
SQL vs. Document-oriented database
The next part is the crux of the actual process happening in this script. To understand how this works you need to be familiar with the MongoDB aggregation framework. A task like this will take way too much code if you start writing SQL. Most relational databases and also Spark offer SQL as a way to process and aggregate their data. The most common reason I have heard from managers to take that approach is - "it is easy". That works, but it is too verbose. That is why I personally prefer to use the aggregation framework of MongoDB to do my pre-processing since I can operate much faster than the other tools out there. It may not be "easy" as per the common belief, but a bit more effort in studying the aggregation framework pays off - saving a lot of development effort.
What about execution time? These scripts execute on the database nodes - inside the database. Thus you cannot make it any faster - since most of the time spent in dealing with large data is in transporting the data from the storage nodes to the execution nodes. In the case of the aggregation frameworks, you are getting all benefits of BigData for free. You are actually using in-database analytics here for the fastest execution time.
This nifty script above does a lot of things. The first thing to note in this script is that we are operating on a live database that has a constant stream of data coming in. Thus in order to select some records for processing we need to decide the time range first and only select those that fall within that time range. The next time we run this script, the records that could not be picked up this time, will be gathered and processed. This is all being done within the 'match' clause.
The second clause is the 'project' clause - which only selects the four required fields for the next stage of the pipeline. The 'unwind' clause flattens all arrays. The next 'match' clause select the driver name and the final 'sort' clause sorts the data by eventtime in ascending order.
Distance on earth between two points
Before proceeding further, I would like to get one thing out of the way. Since we are dealing with a lot of latitude-longitude pairs and subsequently trying to find displacement, velocity and acceleration, we need a way to calculate the distance between two points on earth. There are several algorithms with varying degree of accuracy, but this is the one I have found to be computationally accurate (if you do not have an algorithm already provided by the database vendor).
We will be using this function in the next analysis. As I said before, our goal is to augment our device records with extra information pertaining to time-derivatives. The following code adds extra fields "interval", "acceleration", "angular_velocity" and "incline" to each device record by comparing it with the preceeding record.
Note that in line 50, I am saving the record in another collection called 'mldataset' which is going to be the collection on which I will apply feature-extraction for driver signatures. The final task is to save the book-keeping values in their respective tables.
Creating the feature set for driver signatures
The next step is to create the feature sets for driver signature analysis. I do this by first reading records from the augmented collection 'mldataset' and aggregating values over every 15 minutes. For each field that contains a number (and it happens to change often), I will calculate three statistical values for each field - the minimum over the time window, the maximum and the average. Interestingly, one can also include other statistical values like variance, kertosis - but I have not tried those in my experiment yet - and is an enhancement that you can do easily.
You will find all the code in the file 'extract_features_from_mldataset.js' under the 'machinelearning' directory.
Let us do some book-keeping first.
Using the last time stamp stored in the system, we can figure out which records are new.
Extracting features for each driver
Now is the time to do the actual feature extraction from the data-set. Here is the entire loop:
For each driver (or rather driver-vehicle combination) that is identified, the first task is to figure out the last processing time for that driver and find all new records (lines 6 to 22). The next task of aggregating over 15 second windows is a MongoDB aggregation step starting from line 27. Aggregation tasks in MongoDB are described as pipeline where element element of the flow does a certain task and passes on the result to the next element in the pipe. The first task is to match all records within the time-span that we want to process (lines 29 to 36). Then we only need to consider (i.e. project) few fields that are of interest to us (lines 38 to 44). The element of the pipeline '\(group') does the actual job of aggregation. The key to this aggregation step is the group-by Id that is created using a 'quarter' (line 55) which is nothing but a number between 0 and 3 created out of the second value of the time-stamp. This effectively creates the time windows needed for aggregation.
The actual aggregation steps are quite repetitive. See for example lines 61 to 63 where the average load, minimum load and maximum load is being calculated based on the aggregate over each time period. This is repeated for all the variables that we want to consider in the feature-set. Before storing it, the values are sorted based on event-time (lines 200 to 202).
Saving the feature-set in a collection
The features thus calculated are saved to a new collection on which I would apply a machine-learning algorithm to create a model. The collection is called 'vehicle_signature_records' - where the feature-set records can be saved as follows:
The code above inserts a few more variables to identify the driver, the vehicle and the driver-vehicle combination to the result sent by the aggregation function (lines 8 to 21) and saves it to the database (line 26). However lines 23 and 24 need an explanation since it signifies something very important and significant!
Coding the approximate location of the driver
One of the interesting observations I discovered while working on this problem is that one can dramatically improve accuracy of prediction if you can code the approximate location of the driver. Imagine working on this problem for millions of drivers who are scattered all across the country. One of the important facts to consider is that most drivers generally drive around a certain location most of the time. Thus if their location is somehow encoded into the model, the model can quickly converge based on their location. Lines 23 and 24 attempt to do just that. It encodes two numbers that represent the approximate latitude and longitude of the location. All these lines do is store the latitude and longitude with reduced accuracy.
Some more book-keeping
As a final step the final task is to store the book-keeping values.
After doing all this work (which by now you may be already exhausted after reading through), we are finally ready to apply some real machine-learning algorithms. Remember, I said before that 95% of the task of a data scientist is in preparing, collecting, consolidating and cleaning the data. You are seeing a live example of that!
In big companies there are people called data-engineers who would do part of this job, but not all people are fortunate enough to have data-engineers working for them. Besides, if you can do all this work, you are more indispensible to the company you work for - and so it makes sense to develop these skills along with your analysis skills as a data-scientist.
Building a Machine Learning Model
Fortunately, the data has been created in a clean way, so there is no further clean-up required on it. Our data is in a MongoDB collection called 'vehicle_signature_records'. If you are a pure Data Scientist the following should be very familar to you. The only difference between what I am going to do now and what you generally find in books and blogs, is the data-source. I am going to read my data-sets directly from the MongoDB database instead of from CSV files. After reading the above, by now you must have become partial experts at understanding MongoDB document structures. If not, don't worry since all the data that we stored in the collection are all flat - i.e. all values are present at the top level of each record. To illlustrate how the data looks, let me show you one record from the collection.
That's quite a number of values for analysis! Which is a good sign for us - more values gives us more options to play with it.
As you may have realized by now, I have come to the final stage of building the model which is a traditional machine-learning task that is usually done in Python or R. So the final piece will be written in Python. You will find the entire code at 'driver_signature_build_model_scikit.py' in the 'machinelearning' directory.
Feature selection and elimination
As is common in any data-science project, one must first take a look at the data and determine if any features need to be eliminated. If some features do not make sense for the model we are building then those features need to be dropped. One quick observation is that fuel pressure and incline has nothing to do with driver signatures. So I will eliminate those values from any further consideration.
Specifically for this problem, you need do something special, which is a bit unusual, but required in this scenario.
If you look at the features carefully you will notice that some features are driver characteristics while others are vehicle characteristics. Thus it is important to not mix up the two sets. I have used my judgement to separate out the features into two sets as follows.
Having done this, now we need to build two different models - one to predict the driver and another one to predict the vehicle. It will be an interesting exercise to see which of these two models have better accuracy.
Reading directly from database instead of CSV
For completeness sake let me first give you two utility functions that are used to pull data out of the MongoDB database.
The function above is Pandas-friendly - it reads data from the MongoDB database and returns a Pandas data-frame so that you can get to work immediately with your machine-learning part.
In case you are not comfortable with MongoDB, I am giving you the entire dataset of the aggregated values in CSV format so that you can import it in any database you wish. The file is in GZIP format - so you need to unzip it before reading it. For those of you who are comfortable with MongoDB, here is the entire database dump.
Building a Machine Learning model
Now it is time to build the learning model. At program invocation two parameters are needed - the database host and which feature set to build the model for. This is handled in the code as follows:
Then I have some logic for setting the appropriate feature set within the application.
The following part is mostly boiler-plate code to break up the dataset into a training set, test set and validation set. While doing so all null values are set to zero as well.
Building a Random Forest Classifier and saving it
After trying out various different classifiers, with this dataset, it turns out that a Random Forest classifier gives the best accuracy. Here is the graph showing accuracy of the different classifiers used with this data set. The two best algorithms turn out to be Classification & Regression and Random Forest Classifier. I chose the Random Forest Classifier since this is an ensamble techique and will have better resilience.

This is what you need to do to build a Random Forest classifier with this dataset.
After building the model, I am saving it in a file (line 4) so that it can be read easily when doing the prediction. To find out how well the model is doing, we have to use the test set to make a prediction and evaluate the model score.
Many kinds of evalution metrics are calculated and printed in the above code segment. The most important one that I tend to look at is the overall model score, but the others will give you a good idea of the bias and variance which indicates how resilient your model is with respect to changing values.
Measure of importance
One interesting analysis is to figure out which of the features is the most impactful on the result. This can be done using the simple code fragment below:
Prediction results and Conclusion
After running the two cases, namely driver prediction and vehicle prediciton, I am typically getting the following scores.
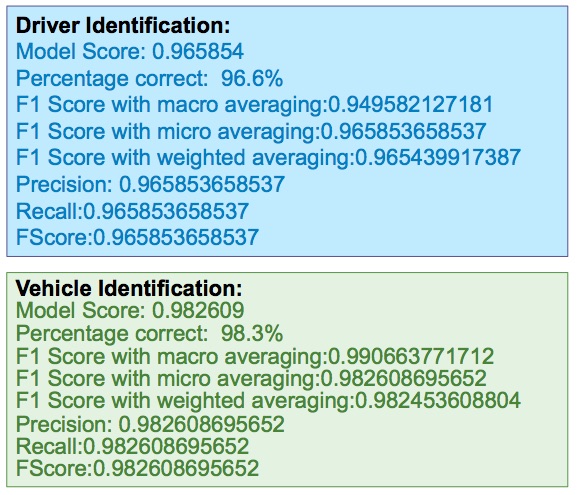
This is encouraging given that there was always an apprehension about the score not being accurate enough due to the low frequency of data collection. This is an important factor, since we are creating this model out of the instantaneous time derivatives of values, and a low sampling rate will introduce a significant error. The dataset has 13 different driver vehicle combinations. There isn't a whole lot of driving data other than the experiments that were done, but with an accuracy that is 95% or above, there may be some value in this approach.
Another interesting fact is that the vehicle prediction is coming out to be more accurate than the driver. In other words, the parameters being emitted by the car tend to characterize the car more heavily than the driver. Most drivers drive the same way, but the machine characteristics of the car tend to distinguish them more clearly.
Commercial Use Cases
I have showed you an example of many such applications that can be done with an approach like this. It just involves equipping your car with a smart device like a Raspberry Pi and the rest is all backend server-side work. Here are all the use-cases that I can think of. You can take up any of these as your own project and attempt to find a solution.
- Parking assistance
- Adaptive collision detection
- Video evidence recording
- Detect abusive driving
- Crash detection
- Theft detection
- Parking meter
- Mobile hot-spot
- Voice recognition
- Connect racing equipment
- Head Unit display
- Traffic sign warning
- Pattern of usage
- Reset fault codes
- Driver recognition (this is already demonstrated here!)
- Emergency braking alert
- Animal overheating protection
- Remote start
- Remote seatbelt notifications
- Radio volume regulation
- Auto radio off when window down
- Eco-driving optimization alerts
- Auto lock/unlock
Commercial product
After doing this experiment building a Raspberry Pi kit from scratch, I found out that there is a product called AutoPi that you can buy which will cut short a lot of the hardware setup. I have no affiliation with AutoPi, but I thought it is interesting that this subject is being treated quite seriously by some companies in Europe.
Driver Signatures from Car Diagnostic Data captured using a Raspberry Pi: Part 2 (Reading real-time data and uploading to the cloud)

This is the second article of the series to determine driver signatures from OBD data using a Raspberry Pi. In the first article I had described in detail how to construct your Raspberry Pi. Now let us write some code to read data from your car and put it to the test. In this second article I will describe the software needed to read data from your car's CAN bus, including some data captured from the GPS antenna attached to your Raspberry Pi, combine it into one packet and send it over to the cloud. I will show you the software setup for capturing data on the client (the Raspberry Pi), store it locally, compress that data on a periodic basis, encrypt it and send it to a cloud server. I will also show you the server setup you need on the cloud to receive the data coming in from the Raspberry Pi, decrypt it and store it in a database or push it to a messaging queue for streaming purposes. All work will be done in Python. My database of choice is MongoDB for this project.
Before you read this article, I would encourage you to read the first article of this series so that you know what hardware setup you need to reproduce this yourself.
Capturing OBD data locally
To begin with let us first see how we can capture data on the Raspberry Pi and save it locally. Since this is the first task that needs to be accomplished, let us figure out a way to capture data constantly and save it somewhere. Our data transmittal task is actually achieved using two processes.
- Capture data constantly and keep saving it to a local database.
- Periodically (once a minute in our case) summarize the data collected since the last successful run, and send it over to the cloud database.
Since we are going to execute a lot of code, I am only going to illustrate the salient features of the solution. A lot of the simpler programming nuances are left for you to figure out by looking at the code.
Did I say looking at the code? Where is it? Well, the entire code-base for this problem is in Github at https://github.com/anupambagchi/driver-signature-raspberry-pi You can clone this repository on your machine and go through the details. Note that I was successful in running this code only on a Raspberry Pi running Ubuntu Mate. I had some trouble installing the required module gps on a Mac, but it runs fine on a Raspberry Pi where it is supposed to run. Most of the modules required by the Python program can be obtained using the 'pip' command, e.g 'pip install crypto'. To get the gps module you need to do 'sudo apt-get install python-gps'.
Where to store the data on a Raspberry Pi?
Remember that the Raspberry Pi is a small device with small memory and possibly small disk space. You need to choose a database that is nimble but effective for this scenario. We do not need any multi-threading ability, nor do we need to store months worth of data. The database is mostly going to be used to collect transitional data that will shortly be compacted and sent over to the cloud database.
 The universal database for this purpose is the in-built SQLite database that comes with every Linux installation. It is a file-based database - which means one has to specify a file when instantiating this database. Make a clone of the repository at the '/opt' directory on your Raspberry Pi.
The universal database for this purpose is the in-built SQLite database that comes with every Linux installation. It is a file-based database - which means one has to specify a file when instantiating this database. Make a clone of the repository at the '/opt' directory on your Raspberry Pi.
You will find a file called /opt/driver-signature-raspberry-pi/create_table_statements.sql and two other files with the extension '.db' which are your database files for running the job.
To initialize the database, you will need to run some initialization script. This is a one-time process on your Raspberry Pi. The SQL statements to set up the database tables are as follows:
To run it, you need to invoke the following:
This will create the necessary tables into the database file 'obd2data.db '.
Capturing OBD data
Now let us focus on capturing the OBD data. For this we make use of a popular Python library called pyobd which may be found at https://github.com/peterh/pyobd. There have been many forks of this library over the past 8 years or so. However my repository adds a lot to it - mainly for cloud processing and machine learning - so I decided not to call it a fork since the original purpose of the library has been altered a lot. I also modified the code to work well with Python 3.
The main program to read data from the OBD port and save it to a SQLite3 database may be found in 'obd_sqlite_recorder.py'. You can refer to this file under 'src' folder while you read the following.
To invoke this program you have to pass two parameters - the name of the user and a string representing the vehicle. For the latter I generally use a convention '<make>-<model>-<year>' for example 'gmc-denali-2015'. Let us now go through the salient features of the OBD scanner.
After doing some basic sanity tests, such as whether the program is running as superuser or not, and whether the appropriate number of parameters have been passed or not, the next step is to search the ports for GSM modem and initialize it.
Once this is done, we need to clean up anything that is 15 days or older so that the database does not grow any bigger. The expectation is that that data is too old and should have been transmitted to the cloud long ago, so we should clean it up to keep the database healthy.
Notice that we are opening up the database connection and executing a SQL statement to clean up and purge the data that is older than 15 days.
Next it is time to connect to the OBD port. Check if the connection can be established, and if not exit the program. Before you run this program, you need to use your Bluetooth settings on the desktop to connect to the ELM 327 device that should be alive and available for connection as soon as you turn the ignition switch on. This connection may be done manually by using the Linux Desktop UI or through a program that automatically does the connection as soon as the machine comes alive.
Notice that we first start the GPS poller. Then attempt to connect to the OBD recorder, and exit the program if unsuccessful.
Now that all connections have been checked, it is time to do the actual job of recording the readings.
A few lines of this code need explanation. The readings are stored in the variable 'results'. This is a dictionary that is first populated through a call to obd_recorder.get_obd_data() [Line 18]. This loops through all the required variables that we need to measure and goes through a loop to measure the values. This dictionary is then augmented with the DTC codes, if any codes are found [Line 22]. DTC stands for Diagnostic Troubleshooting Code and are codes set by the manufacturer to represent some error conditions inside the vehicle or engine. In lines 27-31, the results dictionary is augmented with the username, vehicle and mobile SIM card parameters. Finally in lines 34-41 we add the GPS readings.
So you see that each reading contains information from various sources - the CAN bus, SIM card, user-provided data and GPS signals.
When all data is gathered in the record, we save it in the database (Line 47-48) and commit the changes.
Uploading the data to the cloud
Note that all the data that has been saved so far has not left the machine - it is stored locally inside the machine. Now it is time to work on a mechanism to send it over to the cloud. This data must be
- summarized
- compressed
- encrypted
before we can upload it to our server. On the server side, that same record needs to be decrypted, uncompressed and then stored in a more persistent storage where one can do some BigData analysis. At the same time it needs to be streamed to a messaging queue to make it available for stream processing - mainly for alerting purposes.
Stability and Thread-safety
The driver for uploading data to the cloud is a cronjob that runs every minute. We could also write a program with an internal timer that runs like a daemon, but after a lot of experimentation - specially with large data-sets, I have realized that running an internal timer leads to instability over the long run. When a program runs for ever, it may build up some garbage in the heap over time and ultimately freezes. When a program is invoked through a cronjob, it wakes up, runs, does its job for that moment and exits. That way it always stays out of the way of the data collection program and keeps the machine healthy.
On the same lines, I also need to mention something about thread-safety pertaining to SQLite3. The new task that I am about to attempt is summarization of the data collected by the recorder. So I can technically use the same database that runs from this single file called obd2data.db - right? Not so fast. Because the recorder runs in an infinite loop and constantly writes data to this database, if you attempt to write another table to this same database, it runs into thread-safety issues and the table gets corrupted. I tried this initially, then realized that this was not a stable architecture when I saw it frozen or found data-corruption. So I had to alter it to write the summary to a different database - leaving the raw data database in read-only mode.
Data Compactor and Transmitter
To accomplish the task of transmitting the summarized data to the cloud, let us write a class that fulfils this task. You will find this is the file obd_transmitter.py.
The main loop that does the task is as follows:
There are three tasks - collect, transmit and cleanup. Let us take a look at each of these individually.
Collect and summarize
The following code will create packets of data for each minute, encrypt it, compress it and then transmit it. There are finer details in each of these steps that I am going to explain. But let's look at the code first.
To do some book-keeping (lines 2 to 13), I am keeping the last-processed Id in a separate table. Every time I successfully process a bunch of records, I save the last-processed Id in this table to pick up from during the next run. Remember, this is program is being triggered from a cronjob that runs every minute. You will find the cron description in the file crontab.txt under scripts directory.
Then we collect all the new records (lines 15 to 40) from the CAR_READINGS table and collect it in an array allRecords where each item is a rich document extracted from the JSON payload. One important point to note is that we do not include the current minute - since it may be incomplete. In lines 42 to 56 we are attempting to find out how many minutes have elapsed since the last time it was summarized and then pick up only those whole minutes which remain to be summarized and sent over. In Line 60 we are opening up a connection to a new database (stored in a different file - obd2summarydata.db) to store the summary data.
Lines 62 to 86 does the task of actually creating the summarized packet. Each packet has three fields - the time stamp (only minute, no seconds), the packet of all data collected during the minute, and the summary data (i.e aggregates over the minute). First this packet is created using a summarize function that I will describe later. Then this packet is encrypted using a randomly generated encryption key (Line 73) using AES encryption. Since the data packet size is non-uniform, we encrypt the packet using a randomly-generated key and then send the key over to the server in encrypted form to decrypt the packet. The encrypted packet is compressed (Line 78) to prepare it for transmission. The last step is to encrypt the transmission key itself so that it can also be sent over to the server in the same payload. We use PKS1 OAEP Encryption for this using a public key (encryption.key) stored on the server. The eventtime (whole minute), compressed/encrypted packet, encrypted key and the datasize is saved as a record in the table PROCESSED_READINGS (Line 86).
Note that when the packet is created you have a choice to only send the summarized data or the entire raw records along with the summarized data. It is obvious that if you want to save bandwidth you would do most of the "edge-processing" work in the Raspberry Pi itself and only send the summary record each time. However, in this experiment I wanted to do some additional work on the cloud - which was more granular than the once-a-minute scenario. As shown in part 3 of this series of articles, I actually do the summarization once every 15 seconds for driver signature analysis. So I needed to send all the raw data as well as the summary in my packet - there by increasing the bandwidth requirements. However the compression of data helped a lot is reducing the size of the original packet by almost 90%.
Data Aggregation
Let me now describe how the summarization is done. This is the "edge-computing" part of the entire process that is difficult to do within generic devices. Any IoT device (CalAmp for example) will be able to do most of the work pertaining to capturing OBD data and transmiting it to the cloud. But those devices perhaps are not capable enough to do the summarization - which is why one needs a more powerful computing machine like a Raspberry Pi to do the job. All I do for summarization is the following:
Look at line 56 of the previous block of code. You will see an array of items describing all the items that we need to summarize. This is in the variable summarizationItems. For each item in this list, we need to find the mean, median, mode, standard deviation, variance, maximum and minimum during each minute (Lines 11 to 17). The summarized items are appended to each record before it is saved to the summary database.
Transmitting the data to the cloud
To transmit the data over to the cloud you need to first set up an end-point. I am going to show you later how you can do that on the server. For now, let us assume that you already have that available. Then from the client side you can do the following to transmit the data:
The end-point (that I am going to show you later) will accept POST requests. But you also need to configure a load-balancer that just allows a connection from the outside world to inside the firewall. You must establish adequate security measures to ensure that your tunnel only exposes a certain port on the internal server.
Lines 1 to 7 set up the database connections to the summary database. In the table I am storing a flag "TRANSMITTED" that indicates if the record has been transmitted or not. For all records that have not been transmitted (Line 9) I am creating a payload comprising of size of packet, the encrypted key to use for decrypting the packet, the compressed/encrypted data packet and the eventtime (Line 17). Then this payload is POSTed to the end-point (Line 18). If the transmission is successful, the flag TRANSMITTED is set to true for this packet so that we do not attempt to send this again.
Cleanup
The cleanup operation is pretty simple. All I do is delete all records from the summary table that are more than 15 days old.
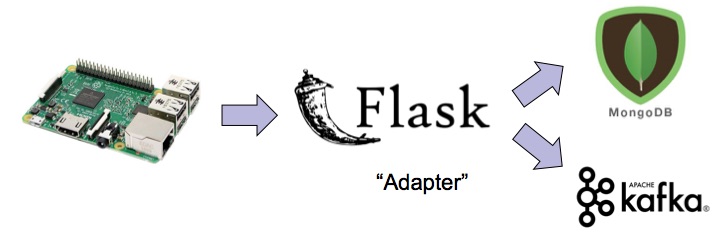
Server on the Cloud
As a final piece to this article let me describe how to set up the end-point of the server. There are many items that are needed to put it together. Surprisingly all of this is achieved in a relatively small amount of code - thanks to the crispness of the Python language.
I decided to use MongoDB as persistent storage for records and Kafka as the messaging server for streaming. The following tasks are done in order in this function:
- Check for invalid usage of this web-service, and raise an exception if illegal (Line 1 to 3). A simple test is done to check for the existence of 'size' in the payload to ensure this.
- Decompress the packet (Line 9 to 10)
- Decrypt the transmission key using the private key (decryption.key) stored on the server. (Line 12 to 14)
- Decrypt the data packet (Line 19)
- Convert the JSON record to an internal Python dictionary for digging deeper into it (Line 21)
- Save the record in MongoDB (Line 27)
- Push the same record into a Kafka messaging queue (Lines 27 to 50)
This functionality is exposed as web-service using a Flask server. You will find the rest of the server code in file flaskserver.py in folder 'server'.
I have covered the salient features to put this together, skipping the other obvious pieces which you can peruse yourself by cloning the entire repository.
Conclusion
I know this has been a long post, but I needed to cover a lot of things. And we have not even started working on the data-science part. You may have heard that a data scientist spends 90% of the time in preparing data. Well, this task is even bigger - we had to set up the hardware and software to generate raw real-time data and store it in real-time to even start thinking about data science. If you are curious to see a sample of the collected data, you can find it here.
But now that this work is done, and we have taken special care that the generated data is in a nicely formatted form, the rest of the task should be easier. You will find the data science related stuff in the third and final episode of this series.
Driver Signatures from Car Diagnostic Data captured using a Raspberry Pi: Part 1 (Building your Raspberry Pi setup)

The Raspberry Pi is an extremely interesting invention. It is a full-fledged Linux box (literally can be caged inside a plastic box) and it basically allows you to run any program to connect to any other communicating device around it through cables or a Bluetooth adapter. I am going to show you how to build your own system to hook up a Raspberry Pi to your car, then extract diagnostic information from the CAN bus, upload that to the cloud, and then use a streaming API to predict who is driving the vehicle using a learning model created through a periodic backend process. To understand this, you need some basic electrical engineering skills and some exposure to Python programming.
Since all this work is pretty long, I intend to break it up into three parts which I am going to put into three different articles as follows:
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 1 (Building your Raspberry Pi setup)
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 2 (Reading real-time data and uploading to the cloud)
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 3 (Analyzing driver data and making predictions)
You should go through these articles in order. You are currently reading Part 1 of this series.
Building your Raspberry Pi setup
Note that there are several web-sites where people have described how to set up a Raspberry Pi for reading Onboard Diagnostic (OBD) data. So my article here is mostly a repetition. I created my setup by reading those articles and watching YouTube videos. You should do that too. The only difference between my article and their's is that I provide a motive for doing all this work and take it further - i.e. for creating driver signatures. The articles I have seen on other blog sites take you through the process of building a Raspberry Pi setup, but their story ends right there. In my case, that is just chapter one - and the more interesting work of uploading to the cloud and analyzing that data follows after that. For completeness sake, I thus have to describe a few things about the setup that pertains to hardware. Without that you cannot even start the project. So just follow along. If you the handyman type of guy (or gal), roll up your sleeves and build it. It is fun!
To cut the description short, here are a few articles describing the setup with enough pictures to get you started.
I started off by going through the first article given here. My car is slightly old, so I had no way of using the car's monitor for seeing the dashboard. So I decided to hook up an independent monitor with my Raspberry Pi that I can carry along with me as a "kit". Moreover, I needed to try out this setup on different cars and different drivers to build any meaningful model - so it was important for me to make my setup independent of any attachment to a vehicle. What I wanted was to hop on any car, start my system using the car battery, hook up my Raspberry Pi to the OBD's ELM 327 adapter using Bluetooth and run my program. So my setup is a bit different from the other guy's since I also needed to upload all that data on the cloud while the car was in motion. Remember, I said I want to do real-time prediction of the driver, so all data that is being generated has to go to the cloud in real-time (or near real-time) where we will apply a prediction step on a pre-built model to make the prediction.
Bill of Materials (Main Items)
Given below are the accessories you need to purchase for a complete setup. I am giving a picture of the items as well so that you can match it as closely as you can when you purchase them.
Raspberry Pi 3
The first thing you want is a Raspberry Pi 3 computer. Here is how it looks. Search for one on web and purchase it from your country's online retailer.

You will also need to buy a plastic case for this board to protect the components.
Notice that the Pi shown above has an HDMI port for the monitor, an ethernet port, 4 USB ports and an SD card slot.
Monitor
You will need a 7-inch car monitor. Most people hook up the Raspberry Pi to the inbuilt monitor of the car, but my use-case is multi-car. So I wanted to keep my setup independent of any car - thus I went with a separate monitor. Here is what I used for this purpose.

This does not come with an HDMI cable, so I had to purchase a separate cable myself to connect to the Pi. Note that this came with a 110V adapter, so you may choose to either buy a cable to use with your car's cigarette lighter slot, or buy an inverter that converts 12V DC to 110V AC and use that as your universal power source for all situations.
Inverter (Optional)
I decided to go with the DC to AC inverter since that also [1] acts as a spike buster in the car - (note that voltage spikes when you start the car), and [2] you can have just one setup for your power source needs, whether you are inside the car, or sitting in the lab for your post-processing or development needs.
Here is a picture of the inverter I am using:

Keyboard
The next accessory you need is a keyboard to operate your machine. I went with an integrated keyboard/trackpad that goes along with size of the Raspberry Pi. Here is what I liked:

ELM 327 Adapter
To connect to your car, your Raspberry Pi needs a Bluetooth adapter. The ELM 327 standard allows a serial connection your car's CAN bus. This adapter can access your car's CAN bus data via a serial connection. Note that this is a slow connection (being serial), but we will try to manage with this. The connector is pretty cheap (around USD 10 or so). I have seen more advanced connectors from Kvaser that come in the range of $300 or so, and can read data at a much faster rate. Our connector will be able to read data at a reasonable rate, but not fast enough for highly accurate readings. We will live with it.
Here is how it looks.

You need to insert this into your car's OBD2 port which is generally found under the steering wheel of your car. It is generally above your left foot, and the port looks like this.

GSM modem
Since we intend to upload our data to the cloud in real-time, we will need a GSM modem. There are many choices and the software setup is different for different vendors. I went with a TELUS modem that uses a Huawei chip internally.

You will notice that this is where our setup goes beyond the other setups found on the internet.
GPS Antenna
Another important component we need is the GPS antenna. This is not really necessary for the driver signature part, but it is very important for visualization of data and to do other kinds of analysis - like speed and acceleration calculations from GPS data. Here is one that goes with the Raspberry Pi.

You need to follow the manual for connecting this to your Raspberry Pi. I had to do some soldering work in order to make the right connections. The software to drive this also needs to be installed via a 'apt-get' command.
Complete Kit
My complete kit after putting together all the components looks like this:

You can see that I decided to mount all of this on a two-layered particle board separated with plastic pipes. Even though it looks big, it is not clunky. There is enough room for expansion. I kept it in two layers so that all the power cables are hidden underneath the top board and exist out of view. You will need some velcro strips to keep the power supply units from falling away. I also used a USB extender (Inateck) to keep my USB devices from clogging up room around the Raspberry Pi.
This setup is clean and portable. You can use it to work and debug code inside your car or in the lab.
Conclusion
My setup was inspired by many articles on the web and on YouTube. You should also consult other links that show you how to do it. However this is not the main focus of this series - my main objective is to use this setup for some data science purpose. I chose to use this for driver signature analysis. The following two articles will delve deeper into the software setup - both on the client side and the server side, to solve this problem. You will find the links to the next two articles under. Happy reading!
Predicting sensor failure based on voltage readings

Let us try to apply the principles of churn for a use-case involving sensors and devices. In this post we will apply some machine learning principles to predict which devices are likely to fail in future. The scenario is as follows:
Problem Description
A company is in the business of allocating car parking space to visitors. For that, it needs to have sensors installed at each parking space. These sensors are installed on the ground right under where the car is supposed to park. When a car comes over it, it senses the presence of the car through a set of five proximity sensors that then give a reading in analog voltages. These set of five readings would indicate if there is a car present above it. This data is then transmitted periodically over the network to the server where it is recorded. On the other hand, one can also send control messages over the cellular network to the sensors from the servers to take some action, like calibrate itself or reboot the device.  Sensor under the car senses an object above it by sending ultra-sonic waves[/caption] These sensors need to be really hardy. They can be driven upon by cars. They have to weather the sun's direct sunlight when there is no vehicle over it. They also have to weather the rain and the battery must last for a long time. Over time, though, the battery becomes weak, or the sensors themselves lose their ability to sense correctly, and then finally die. The engineers who are operating these sensors have noticed that every time they send a signal to reboot the device, some of the devices do not show up any more. This happens because during a power-cycle reboot, the sensor goes through some stress and, depending on network connection in that area, it takes up to 24 hours for the device to reconnect to the network and send its data. Thus it is known that sensors generally die after a power-cycle reboot. If data has not been received from the sensor for 24 hours, that device is most likely dead. We have a record of all sensors that were operational before and after the last reboot operation. A few of the devices stopped transmitting after that reboot event. The problem is to predict which devices are likely to die during the next reboot event.
Sensor under the car senses an object above it by sending ultra-sonic waves[/caption] These sensors need to be really hardy. They can be driven upon by cars. They have to weather the sun's direct sunlight when there is no vehicle over it. They also have to weather the rain and the battery must last for a long time. Over time, though, the battery becomes weak, or the sensors themselves lose their ability to sense correctly, and then finally die. The engineers who are operating these sensors have noticed that every time they send a signal to reboot the device, some of the devices do not show up any more. This happens because during a power-cycle reboot, the sensor goes through some stress and, depending on network connection in that area, it takes up to 24 hours for the device to reconnect to the network and send its data. Thus it is known that sensors generally die after a power-cycle reboot. If data has not been received from the sensor for 24 hours, that device is most likely dead. We have a record of all sensors that were operational before and after the last reboot operation. A few of the devices stopped transmitting after that reboot event. The problem is to predict which devices are likely to die during the next reboot event.
Analyzing the data set
Before we attempt to solve this problem, let us take a look at some sample data. Note that in real-life situations the data is going to be noisy, messy and sometimes inaccurate. As a data scientist, one has to make a judicious choice as to whether it should be used or not. This elimination process must be applied to columns as well as rows. 
We will analyze the columns one-by-one and make a decision to keep it or discard it.
- The first column appears to just a row Id. Thus it has no contribution to the data-model; so we discard it.
- The second column (mac) is the device id. This is the unique Id of the device, so we need to use it for predicting which devices are likely to die during the next power-cycle reboot.
- The third column (mj) does not change, so it has no effect on the data-model; thus it is discarded.
- The fourth column (fw) is same for all rows - a candidate for discarding it.
- The fifth column (time) is important. It tells us when the device data was received - thus we can actually see which devices were alive and dead after the last power cycle reboot.
- The sixth column (uamps) has no value since it is same for all rows; discard it.
- The seventh column (batt_v) appears to be the most important field of all. It is the battery voltage which has the highest impact on the life of a device stranded in the open space.
- The eighth field (cc) is a numeric measured value from the environment. We will keep it and observe if it has any impact on the life of the device.
- The ninth field (temp) is the temperature of the device at the time the reading was taken. We'll keep it.
- The tenth field (diag) may be discarded since it is zero all across.
- The eleventh field (mahrs_consumed) may also be discarded.
- The twelfth field (avg_lifetime_uamps) is not coming through correctly, so we discard it.
- The thirteenth field (missed_payloads) seems like an interesting field since it would have indicated the signal strength around that area, but unfortunately it is not coming through; so we discard it.
- The fourteenth field (total_time_sec) is zero all across; so discard it.
- The fifteenth field (l0) does have some significance since it is a sensor parameter. We'll keep it.
- The sixteenth field (l1) is also an sensor parameter with changing values. We'll keep that as well.
- The seventeenth field (prod_date) is a the date the device was manufactured. We probably don't have much use of this at the moment, so it will be ignored.
- The eighteenth field (vreg) appears to be important since it has values that change; so we'll keep it.
- The nineteenth field (sleep) has a constant value of zero; discard it.
- The twentieth field (eco) may be kept even though it seems to have little variation.
- The twenty-first field (esr_samples) is interesting since it has four different numeric values embedded inside it. We believe these values can be separated (using ':' as a delimiter) and these can be used individually. Most likely these are the raw voltage readings from the sensors which will have a huge impact on the life of the product. We'll use all four values found in this field.
- The last field (esr_timing) is the setting on the device when the readings in column 21 were taken. This is constant all through, so we discard it for our analysis.
The engineering team has also notified us that the last reboot operation happened on September 29th, 2016.
Problem Approach
Before we start our analysis you need to get the data-set. Get the GZIP file here. Download the file given in the link above and save it to some local folder on your computer. Open up a terminal and change directory to the folder where you downloaded the file. Then unzip the file using:
gunzip sensor_data_001.csv.gz
You will see the data in the file sensor_data_001.csv. You can readily observe that this is not a standard supervised learning problem. For any supervised learning problem we need an X-vector and a y-vector for the training set. We do not know yet how to get the output y-variable since it is not given in the problem directly. Thus for training purposes, the output variable must be derived in some way.
Determining the output y-vector
Look at the data-set carefully. There are 69,765 rows in this data-set. To determine which devices have died during the last reboot operation, one has to first sort this list by date. Fortunately, I have already sorted this data for you by date, so you should be able to see the records from the beginning in order. You will notice that this data-set contains records only for a few days. We need to partition this data-set into two parts.
- All records prior to Sep 29th, since that was the day when the last reboot operation happened. This will be our training set which helps us build out prediction model.
- All records after Sep 29th, to determine which devices survived the reboot operation. This will be our dev set on which we will apply our model to determine the "weak" devices that are likely to die after the next reboot operation.
Having done that, we may be able to determine which devices have died due to the reboot, and thus be able to re-create an additional column for the y-vector.
Problem Solution
Let us get started with the programming exercise. To solve this problem, we will use Python with Pandas, Scikit-Learn. Our goal is to write the entire solution in one file without multiple passes. Thus it will involve use of Pandas filtering - the results of which will be in memory.
Before you attempt it on your own machine, you need to ensure that you have the necessary libraries to run this program. Open up a terminal shell and run the following:
After installing these necessary packages, we are ready to begin. I will describe the different stages of the task as different steps.
Step 1: Set up import statements
Let us first import a few necessary libraries:
Step 2: Read the CSV file and identify the column names.
We now need to open the data file and read the column names. Pandas has handy functions to do that.
Step 3: Build the data-frames
The next step is to build the data frames in Pandas. While doing that we need to do certain transformations since some fields that contain numbers or dates are appearing in the data file as strings.
- First we need to convert the string variables found in column time_stamp into timestamps.
- Secondly, we need to pluck out the individual values from the field esr_samples into four different values. These are the individual sensor voltage readings that we believe have significant impact on the life of the sensor.
Notice that we are creating four new columns in the data frame with names esr0, esr1, esr2 and esr3. Then we are concatenating the newly generated data-frame with the original data-frame making it wider.
Step 4: Choosing the training set
Recall that I said, we need to look at the rows prior to the last reboot operation on Sep 29 to determine which devices were alive then and compare them with those found later. This helps us figure out which devices have died during the reboot.
I created a Pandas filter to separate out the the rows prior to the cut-off date. Then I used the Pandas unique() function to figure out all the device Ids that existed during that time. When I use the same unique() function on the rows after the cut-off date, I get all sensors that are alive later.
My goal is to create another Y-column (isalive) which has values 0 or 1 - where 0 represents dead and 1 represents alive. I do so by using the Pandas np.where() function and augmenting that information in the data-frame containing rows prior to Sep 29. This will be my training set.
For your reference here is the full set of columns in the original dataset:
Step 5: Setting up the training task
Now it is time to set up the training task. I first create a list of columns to be used for the output vector, and also another set for all the input variables - or features.
A lot of what follows next is boiler-plate code that you can use for any generic data-science problem. I have been using this boiler-plate as my starting point for any coding problem that I want to use with Pandas and Sckit-Learn.
Note that we have all our training data in the data-frame named running_before_reboot_df. Typically, we would take a small sample out of this data-frame to verify the accuracy of the prediction. In this situation we can use the entire data-frame as our training set since we have already separated out the validation set (those records after Sep 29). But for demonstration purposes, I am going to still create a test set from the data-frame to create the confusion matrix and an F-score.
I am creating above two data-frames, one for training and another for testing. 80% of the data is being used for training.
To avoid any problems with missing values, I am also filling with zeros all fields that do not have a value.
Step 6: Setting up the validation set for prediction
Similarly, one can set up the prediction set by taking records that were after the cut-off date.
Step 7: Training the data-model
Now it is time to train the model with the data-frames created so far. We choose to use the Random Forest classifier for this purpose. Through experience I have discovered that ensemble learning provides the best results since it uses multiple approaches to solve the problem and then chooses the few best among those.
Step 8: Validating the model and finding accuracy
For data scientists most of the time is spent in validating and tuning the model. I am giving below the necessary code to print out the Confusion Matrix along with the Precision, Recall and F-score.
If you run this, you will see that the model score come out as 82% accurate. This is not perfect, but it is perhaps the best what our data-set allows. Remember that we are dealing with noisy data, and trying to come up with a prediction based on that data-set without doing any further filtering.
One of the interesting results coming from this analysis is finding out which parameters have the most impact on a sensor's death. For that, one has to look at the feature importance numbers. Looking at the numbers, one can see that esr3 has the most impact, followed by battery voltage and then esr2 and esr1.
Step 9: Making a prediction based on this data-model
Now that we have created a data-model, let us try to predict how many devices are likely to die during the next reboot.
All I am doing here is using the predict() method provided by Scikit-learn to apply the model on the prediction data-frame. Out of the values that I get as my predicted value of isalive, I am only choosing those that have a value of zero i.e. likely to die.
Step 10: All done, print out the device Ids
Finally it is time to print out the device Ids that were identified to be weak and likely to switch off permanently during the next reboot.
Full output of the program
Given below is the full output of the program. You can see that it provides the list of device ids that are likely to die during the next reboot.
Conclusion
I hope you have enjoyed reading this blog post. You can get the entire code as a single file. A lot of the work depends on knowing the quirks of Pandas and handling data using the Pandas functions. Most people, including myself, think in SQL first and then attempt to find out the Pandas way of doing the same job. I need to keep Google handy for doing searches as I progress through the code. Since I have shown you a lot of the common use-cases, you can take hints from this code and proceed with your own work, using some of the boiler-plate code. If you like this article or find an error in the code, or have an alternate opinion about the approach, you are most welcome to leave a comment below.
Search
Recent Post

© Copyright 2024 Anupam Bagchi