Data Science
Blog articles pertaining to Data Science, Machine Learning, Hardware, Software and Personal musings
Driver Signatures from Car Diagnostic Data captured using a Raspberry Pi: Part 2 (Reading real-time data and uploading to the cloud)

This is the second article of the series to determine driver signatures from OBD data using a Raspberry Pi. In the first article I had described in detail how to construct your Raspberry Pi. Now let us write some code to read data from your car and put it to the test. In this second article I will describe the software needed to read data from your car's CAN bus, including some data captured from the GPS antenna attached to your Raspberry Pi, combine it into one packet and send it over to the cloud. I will show you the software setup for capturing data on the client (the Raspberry Pi), store it locally, compress that data on a periodic basis, encrypt it and send it to a cloud server. I will also show you the server setup you need on the cloud to receive the data coming in from the Raspberry Pi, decrypt it and store it in a database or push it to a messaging queue for streaming purposes. All work will be done in Python. My database of choice is MongoDB for this project.
Before you read this article, I would encourage you to read the first article of this series so that you know what hardware setup you need to reproduce this yourself.
Capturing OBD data locally
To begin with let us first see how we can capture data on the Raspberry Pi and save it locally. Since this is the first task that needs to be accomplished, let us figure out a way to capture data constantly and save it somewhere. Our data transmittal task is actually achieved using two processes.
- Capture data constantly and keep saving it to a local database.
- Periodically (once a minute in our case) summarize the data collected since the last successful run, and send it over to the cloud database.
Since we are going to execute a lot of code, I am only going to illustrate the salient features of the solution. A lot of the simpler programming nuances are left for you to figure out by looking at the code.
Did I say looking at the code? Where is it? Well, the entire code-base for this problem is in Github at https://github.com/anupambagchi/driver-signature-raspberry-pi You can clone this repository on your machine and go through the details. Note that I was successful in running this code only on a Raspberry Pi running Ubuntu Mate. I had some trouble installing the required module gps on a Mac, but it runs fine on a Raspberry Pi where it is supposed to run. Most of the modules required by the Python program can be obtained using the 'pip' command, e.g 'pip install crypto'. To get the gps module you need to do 'sudo apt-get install python-gps'.
Where to store the data on a Raspberry Pi?
Remember that the Raspberry Pi is a small device with small memory and possibly small disk space. You need to choose a database that is nimble but effective for this scenario. We do not need any multi-threading ability, nor do we need to store months worth of data. The database is mostly going to be used to collect transitional data that will shortly be compacted and sent over to the cloud database.
 The universal database for this purpose is the in-built SQLite database that comes with every Linux installation. It is a file-based database - which means one has to specify a file when instantiating this database. Make a clone of the repository at the '/opt' directory on your Raspberry Pi.
The universal database for this purpose is the in-built SQLite database that comes with every Linux installation. It is a file-based database - which means one has to specify a file when instantiating this database. Make a clone of the repository at the '/opt' directory on your Raspberry Pi.
You will find a file called /opt/driver-signature-raspberry-pi/create_table_statements.sql and two other files with the extension '.db' which are your database files for running the job.
To initialize the database, you will need to run some initialization script. This is a one-time process on your Raspberry Pi. The SQL statements to set up the database tables are as follows:
To run it, you need to invoke the following:
This will create the necessary tables into the database file 'obd2data.db '.
Capturing OBD data
Now let us focus on capturing the OBD data. For this we make use of a popular Python library called pyobd which may be found at https://github.com/peterh/pyobd. There have been many forks of this library over the past 8 years or so. However my repository adds a lot to it - mainly for cloud processing and machine learning - so I decided not to call it a fork since the original purpose of the library has been altered a lot. I also modified the code to work well with Python 3.
The main program to read data from the OBD port and save it to a SQLite3 database may be found in 'obd_sqlite_recorder.py'. You can refer to this file under 'src' folder while you read the following.
To invoke this program you have to pass two parameters - the name of the user and a string representing the vehicle. For the latter I generally use a convention '<make>-<model>-<year>' for example 'gmc-denali-2015'. Let us now go through the salient features of the OBD scanner.
After doing some basic sanity tests, such as whether the program is running as superuser or not, and whether the appropriate number of parameters have been passed or not, the next step is to search the ports for GSM modem and initialize it.
Once this is done, we need to clean up anything that is 15 days or older so that the database does not grow any bigger. The expectation is that that data is too old and should have been transmitted to the cloud long ago, so we should clean it up to keep the database healthy.
Notice that we are opening up the database connection and executing a SQL statement to clean up and purge the data that is older than 15 days.
Next it is time to connect to the OBD port. Check if the connection can be established, and if not exit the program. Before you run this program, you need to use your Bluetooth settings on the desktop to connect to the ELM 327 device that should be alive and available for connection as soon as you turn the ignition switch on. This connection may be done manually by using the Linux Desktop UI or through a program that automatically does the connection as soon as the machine comes alive.
Notice that we first start the GPS poller. Then attempt to connect to the OBD recorder, and exit the program if unsuccessful.
Now that all connections have been checked, it is time to do the actual job of recording the readings.
A few lines of this code need explanation. The readings are stored in the variable 'results'. This is a dictionary that is first populated through a call to obd_recorder.get_obd_data() [Line 18]. This loops through all the required variables that we need to measure and goes through a loop to measure the values. This dictionary is then augmented with the DTC codes, if any codes are found [Line 22]. DTC stands for Diagnostic Troubleshooting Code and are codes set by the manufacturer to represent some error conditions inside the vehicle or engine. In lines 27-31, the results dictionary is augmented with the username, vehicle and mobile SIM card parameters. Finally in lines 34-41 we add the GPS readings.
So you see that each reading contains information from various sources - the CAN bus, SIM card, user-provided data and GPS signals.
When all data is gathered in the record, we save it in the database (Line 47-48) and commit the changes.
Uploading the data to the cloud
Note that all the data that has been saved so far has not left the machine - it is stored locally inside the machine. Now it is time to work on a mechanism to send it over to the cloud. This data must be
- summarized
- compressed
- encrypted
before we can upload it to our server. On the server side, that same record needs to be decrypted, uncompressed and then stored in a more persistent storage where one can do some BigData analysis. At the same time it needs to be streamed to a messaging queue to make it available for stream processing - mainly for alerting purposes.
Stability and Thread-safety
The driver for uploading data to the cloud is a cronjob that runs every minute. We could also write a program with an internal timer that runs like a daemon, but after a lot of experimentation - specially with large data-sets, I have realized that running an internal timer leads to instability over the long run. When a program runs for ever, it may build up some garbage in the heap over time and ultimately freezes. When a program is invoked through a cronjob, it wakes up, runs, does its job for that moment and exits. That way it always stays out of the way of the data collection program and keeps the machine healthy.
On the same lines, I also need to mention something about thread-safety pertaining to SQLite3. The new task that I am about to attempt is summarization of the data collected by the recorder. So I can technically use the same database that runs from this single file called obd2data.db - right? Not so fast. Because the recorder runs in an infinite loop and constantly writes data to this database, if you attempt to write another table to this same database, it runs into thread-safety issues and the table gets corrupted. I tried this initially, then realized that this was not a stable architecture when I saw it frozen or found data-corruption. So I had to alter it to write the summary to a different database - leaving the raw data database in read-only mode.
Data Compactor and Transmitter
To accomplish the task of transmitting the summarized data to the cloud, let us write a class that fulfils this task. You will find this is the file obd_transmitter.py.
The main loop that does the task is as follows:
There are three tasks - collect, transmit and cleanup. Let us take a look at each of these individually.
Collect and summarize
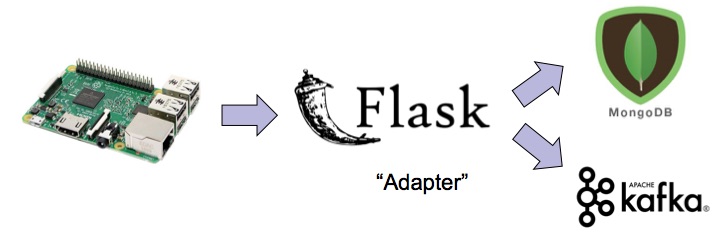
The following code will create packets of data for each minute, encrypt it, compress it and then transmit it. There are finer details in each of these steps that I am going to explain. But let's look at the code first.
To do some book-keeping (lines 2 to 13), I am keeping the last-processed Id in a separate table. Every time I successfully process a bunch of records, I save the last-processed Id in this table to pick up from during the next run. Remember, this is program is being triggered from a cronjob that runs every minute. You will find the cron description in the file crontab.txt under scripts directory.
Then we collect all the new records (lines 15 to 40) from the CAR_READINGS table and collect it in an array allRecords where each item is a rich document extracted from the JSON payload. One important point to note is that we do not include the current minute - since it may be incomplete. In lines 42 to 56 we are attempting to find out how many minutes have elapsed since the last time it was summarized and then pick up only those whole minutes which remain to be summarized and sent over. In Line 60 we are opening up a connection to a new database (stored in a different file - obd2summarydata.db) to store the summary data.
Lines 62 to 86 does the task of actually creating the summarized packet. Each packet has three fields - the time stamp (only minute, no seconds), the packet of all data collected during the minute, and the summary data (i.e aggregates over the minute). First this packet is created using a summarize function that I will describe later. Then this packet is encrypted using a randomly generated encryption key (Line 73) using AES encryption. Since the data packet size is non-uniform, we encrypt the packet using a randomly-generated key and then send the key over to the server in encrypted form to decrypt the packet. The encrypted packet is compressed (Line 78) to prepare it for transmission. The last step is to encrypt the transmission key itself so that it can also be sent over to the server in the same payload. We use PKS1 OAEP Encryption for this using a public key (encryption.key) stored on the server. The eventtime (whole minute), compressed/encrypted packet, encrypted key and the datasize is saved as a record in the table PROCESSED_READINGS (Line 86).
Note that when the packet is created you have a choice to only send the summarized data or the entire raw records along with the summarized data. It is obvious that if you want to save bandwidth you would do most of the "edge-processing" work in the Raspberry Pi itself and only send the summary record each time. However, in this experiment I wanted to do some additional work on the cloud - which was more granular than the once-a-minute scenario. As shown in part 3 of this series of articles, I actually do the summarization once every 15 seconds for driver signature analysis. So I needed to send all the raw data as well as the summary in my packet - there by increasing the bandwidth requirements. However the compression of data helped a lot is reducing the size of the original packet by almost 90%.
Data Aggregation
Let me now describe how the summarization is done. This is the "edge-computing" part of the entire process that is difficult to do within generic devices. Any IoT device (CalAmp for example) will be able to do most of the work pertaining to capturing OBD data and transmiting it to the cloud. But those devices perhaps are not capable enough to do the summarization - which is why one needs a more powerful computing machine like a Raspberry Pi to do the job. All I do for summarization is the following:
Look at line 56 of the previous block of code. You will see an array of items describing all the items that we need to summarize. This is in the variable summarizationItems. For each item in this list, we need to find the mean, median, mode, standard deviation, variance, maximum and minimum during each minute (Lines 11 to 17). The summarized items are appended to each record before it is saved to the summary database.
Transmitting the data to the cloud
To transmit the data over to the cloud you need to first set up an end-point. I am going to show you later how you can do that on the server. For now, let us assume that you already have that available. Then from the client side you can do the following to transmit the data:
The end-point (that I am going to show you later) will accept POST requests. But you also need to configure a load-balancer that just allows a connection from the outside world to inside the firewall. You must establish adequate security measures to ensure that your tunnel only exposes a certain port on the internal server.
Lines 1 to 7 set up the database connections to the summary database. In the table I am storing a flag "TRANSMITTED" that indicates if the record has been transmitted or not. For all records that have not been transmitted (Line 9) I am creating a payload comprising of size of packet, the encrypted key to use for decrypting the packet, the compressed/encrypted data packet and the eventtime (Line 17). Then this payload is POSTed to the end-point (Line 18). If the transmission is successful, the flag TRANSMITTED is set to true for this packet so that we do not attempt to send this again.
Cleanup
The cleanup operation is pretty simple. All I do is delete all records from the summary table that are more than 15 days old.
Server on the Cloud
As a final piece to this article let me describe how to set up the end-point of the server. There are many items that are needed to put it together. Surprisingly all of this is achieved in a relatively small amount of code - thanks to the crispness of the Python language.
I decided to use MongoDB as persistent storage for records and Kafka as the messaging server for streaming. The following tasks are done in order in this function:
- Check for invalid usage of this web-service, and raise an exception if illegal (Line 1 to 3). A simple test is done to check for the existence of 'size' in the payload to ensure this.
- Decompress the packet (Line 9 to 10)
- Decrypt the transmission key using the private key (decryption.key) stored on the server. (Line 12 to 14)
- Decrypt the data packet (Line 19)
- Convert the JSON record to an internal Python dictionary for digging deeper into it (Line 21)
- Save the record in MongoDB (Line 27)
- Push the same record into a Kafka messaging queue (Lines 27 to 50)
This functionality is exposed as web-service using a Flask server. You will find the rest of the server code in file flaskserver.py in folder 'server'.
I have covered the salient features to put this together, skipping the other obvious pieces which you can peruse yourself by cloning the entire repository.
Conclusion
I know this has been a long post, but I needed to cover a lot of things. And we have not even started working on the data-science part. You may have heard that a data scientist spends 90% of the time in preparing data. Well, this task is even bigger - we had to set up the hardware and software to generate raw real-time data and store it in real-time to even start thinking about data science. If you are curious to see a sample of the collected data, you can find it here.
But now that this work is done, and we have taken special care that the generated data is in a nicely formatted form, the rest of the task should be easier. You will find the data science related stuff in the third and final episode of this series.
Driver Signatures from Car Diagnostic Data captured using a Raspberry Pi: Part 1 (Building your Raspberry Pi setup)

The Raspberry Pi is an extremely interesting invention. It is a full-fledged Linux box (literally can be caged inside a plastic box) and it basically allows you to run any program to connect to any other communicating device around it through cables or a Bluetooth adapter. I am going to show you how to build your own system to hook up a Raspberry Pi to your car, then extract diagnostic information from the CAN bus, upload that to the cloud, and then use a streaming API to predict who is driving the vehicle using a learning model created through a periodic backend process. To understand this, you need some basic electrical engineering skills and some exposure to Python programming.
Since all this work is pretty long, I intend to break it up into three parts which I am going to put into three different articles as follows:
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 1 (Building your Raspberry Pi setup)
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 2 (Reading real-time data and uploading to the cloud)
- Driver Signatures from OBD Data captured using a Raspberry Pi: Part 3 (Analyzing driver data and making predictions)
You should go through these articles in order. You are currently reading Part 1 of this series.
Building your Raspberry Pi setup
Note that there are several web-sites where people have described how to set up a Raspberry Pi for reading Onboard Diagnostic (OBD) data. So my article here is mostly a repetition. I created my setup by reading those articles and watching YouTube videos. You should do that too. The only difference between my article and their's is that I provide a motive for doing all this work and take it further - i.e. for creating driver signatures. The articles I have seen on other blog sites take you through the process of building a Raspberry Pi setup, but their story ends right there. In my case, that is just chapter one - and the more interesting work of uploading to the cloud and analyzing that data follows after that. For completeness sake, I thus have to describe a few things about the setup that pertains to hardware. Without that you cannot even start the project. So just follow along. If you the handyman type of guy (or gal), roll up your sleeves and build it. It is fun!
To cut the description short, here are a few articles describing the setup with enough pictures to get you started.
I started off by going through the first article given here. My car is slightly old, so I had no way of using the car's monitor for seeing the dashboard. So I decided to hook up an independent monitor with my Raspberry Pi that I can carry along with me as a "kit". Moreover, I needed to try out this setup on different cars and different drivers to build any meaningful model - so it was important for me to make my setup independent of any attachment to a vehicle. What I wanted was to hop on any car, start my system using the car battery, hook up my Raspberry Pi to the OBD's ELM 327 adapter using Bluetooth and run my program. So my setup is a bit different from the other guy's since I also needed to upload all that data on the cloud while the car was in motion. Remember, I said I want to do real-time prediction of the driver, so all data that is being generated has to go to the cloud in real-time (or near real-time) where we will apply a prediction step on a pre-built model to make the prediction.
Bill of Materials (Main Items)
Given below are the accessories you need to purchase for a complete setup. I am giving a picture of the items as well so that you can match it as closely as you can when you purchase them.
Raspberry Pi 3
The first thing you want is a Raspberry Pi 3 computer. Here is how it looks. Search for one on web and purchase it from your country's online retailer.

You will also need to buy a plastic case for this board to protect the components.
Notice that the Pi shown above has an HDMI port for the monitor, an ethernet port, 4 USB ports and an SD card slot.
Monitor
You will need a 7-inch car monitor. Most people hook up the Raspberry Pi to the inbuilt monitor of the car, but my use-case is multi-car. So I wanted to keep my setup independent of any car - thus I went with a separate monitor. Here is what I used for this purpose.

This does not come with an HDMI cable, so I had to purchase a separate cable myself to connect to the Pi. Note that this came with a 110V adapter, so you may choose to either buy a cable to use with your car's cigarette lighter slot, or buy an inverter that converts 12V DC to 110V AC and use that as your universal power source for all situations.
Inverter (Optional)
I decided to go with the DC to AC inverter since that also [1] acts as a spike buster in the car - (note that voltage spikes when you start the car), and [2] you can have just one setup for your power source needs, whether you are inside the car, or sitting in the lab for your post-processing or development needs.
Here is a picture of the inverter I am using:

Keyboard
The next accessory you need is a keyboard to operate your machine. I went with an integrated keyboard/trackpad that goes along with size of the Raspberry Pi. Here is what I liked:

ELM 327 Adapter
To connect to your car, your Raspberry Pi needs a Bluetooth adapter. The ELM 327 standard allows a serial connection your car's CAN bus. This adapter can access your car's CAN bus data via a serial connection. Note that this is a slow connection (being serial), but we will try to manage with this. The connector is pretty cheap (around USD 10 or so). I have seen more advanced connectors from Kvaser that come in the range of $300 or so, and can read data at a much faster rate. Our connector will be able to read data at a reasonable rate, but not fast enough for highly accurate readings. We will live with it.
Here is how it looks.

You need to insert this into your car's OBD2 port which is generally found under the steering wheel of your car. It is generally above your left foot, and the port looks like this.

GSM modem
Since we intend to upload our data to the cloud in real-time, we will need a GSM modem. There are many choices and the software setup is different for different vendors. I went with a TELUS modem that uses a Huawei chip internally.

You will notice that this is where our setup goes beyond the other setups found on the internet.
GPS Antenna
Another important component we need is the GPS antenna. This is not really necessary for the driver signature part, but it is very important for visualization of data and to do other kinds of analysis - like speed and acceleration calculations from GPS data. Here is one that goes with the Raspberry Pi.

You need to follow the manual for connecting this to your Raspberry Pi. I had to do some soldering work in order to make the right connections. The software to drive this also needs to be installed via a 'apt-get' command.
Complete Kit
My complete kit after putting together all the components looks like this:

You can see that I decided to mount all of this on a two-layered particle board separated with plastic pipes. Even though it looks big, it is not clunky. There is enough room for expansion. I kept it in two layers so that all the power cables are hidden underneath the top board and exist out of view. You will need some velcro strips to keep the power supply units from falling away. I also used a USB extender (Inateck) to keep my USB devices from clogging up room around the Raspberry Pi.
This setup is clean and portable. You can use it to work and debug code inside your car or in the lab.
Conclusion
My setup was inspired by many articles on the web and on YouTube. You should also consult other links that show you how to do it. However this is not the main focus of this series - my main objective is to use this setup for some data science purpose. I chose to use this for driver signature analysis. The following two articles will delve deeper into the software setup - both on the client side and the server side, to solve this problem. You will find the links to the next two articles under. Happy reading!
Search
Recent Post

© Copyright 2024 Anupam Bagchi